














AI and ML
Challenges of applying machine learning models (part 1)

In the first part, we explained the phased approach to applying AI data models. This part will explore the challenges of each stage in greater detail.
One of the main challenges of this phase is combinatorial explosion, multiple data processing steps, and multiple models, resulting in many more data preprocessing and model combinations that need to be compared and verified.
Assuming we are trying to train a classification model on a tabular dataset, we need to pick the column and model combination by selecting one certain column (e.g. Column A) or not and selecting Random Forest or LightGBM as classifier, so there are four different combinations that need to be verified now:
Has Column A, Random Forest model
Has Column A, LightGBM model
No Column A, Random Forest model
No Column A, LightGBM model
Under normal circumstances, we will have more data processing and model selection. As the number of data and model combinations explode, we need to track several key pieces of information for each combination, including the configuration of data processing steps, training data, model hyperparameters, and the model metrics. Such information can help us complete experiment reproducibility.
While completing tasks in the exploration phase, we can use some mature tools. PyCaret ( https://pycaret.org/ ) provides a set of templates that are easy to understand and use to help us accelerate the exploration phase.
In terms of finding the most suitable models, PyCaret first provides a variety of models based on the type of problem to be solved such as Classification, Regression, Anomaly Detection, for each problem, it encapsulates a group of easy to use APIs, allowing users to train and evaluate multiple models at once.
For example, the following figure shows a simple line of compare_models. PyCaret trained 14 different classification models, and recorded a total of 8 metrics such as Accuracy, AUC, and Recall for each model.
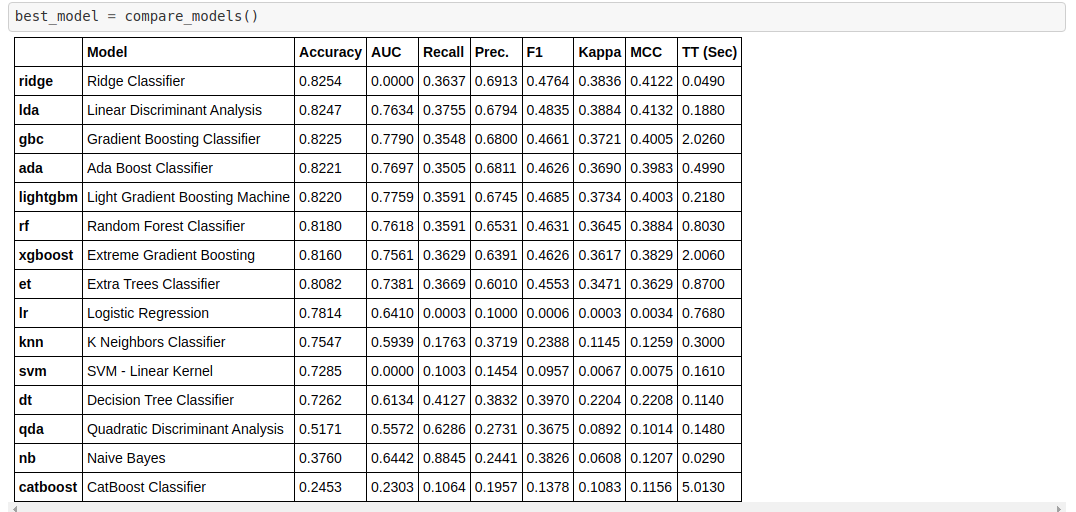
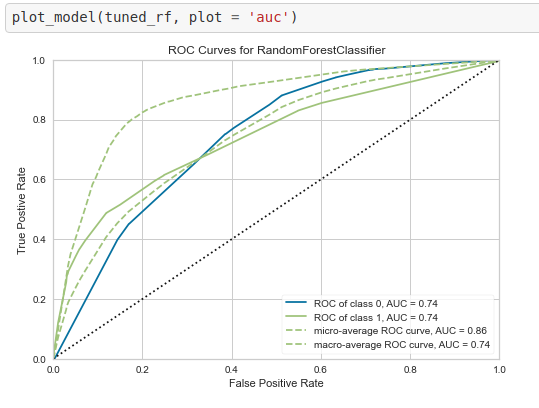
These results are sufficient to make the decision of model selection. If you want to make more detailed comparisons among different models, PyCaret also provides a convenient visualization API that can display the Confusion Matrix, ROC Curve of the classification results. The following figure is a simple plot_model method to draw the ROC Curve of the model tuned_rf.
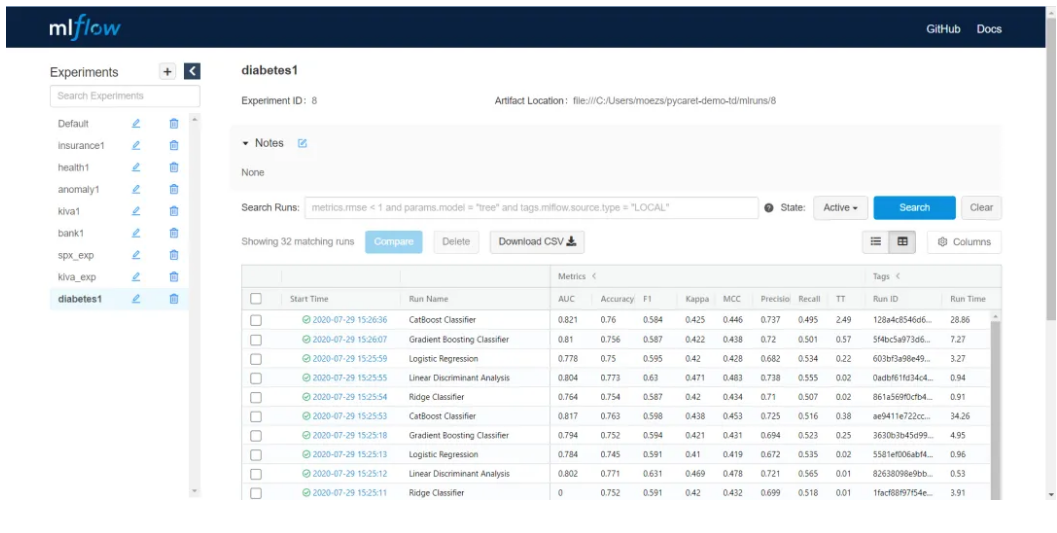
PyCaret provides an easy-to-use logging function that can automatically record the data, model, hyperparameters and results of each model training experiment, and the functionality is based on MLflow. From the figure below, you can see the list of previous experiments, and the corresponding models, indicators, and data of each experiment are recorded simultaneously.
For the problem of data preprocessing, PyCaret also provides common data preprocessing function APIs, such as the SMOTE method to solve the problem of unbalanced data. However, because data processing has a great correlation with the business meaning of the data, in many cases, we still need to design our own processing flow.
PyCaret provides a set of APIs to help to accelerate work like model selection, hyper-parameter selection, metrics comparison, and logging the details of experiments. On the other hand, these APIs also represent a set of reasonable and efficient exploration phase workflows, and significantly reduces the workload of the exploration phase.
The main task of this stage is to productize the data processing process and model while continuously monitoring and updating the model.
At this stage, as the product runs, different versions of the models will be trained. New models need to be used, and old models need to be replaced, which requires a concise and clear model lifecycle management method.
MLFlow provides the function of MLFlow Registry to address the model lifecycle management challenge. It defines the following concepts:
Registered Model: When a model is registered in the Model Registry, it becomes a Registered Model. Each Registered Model has its own distinctive name, version, stage, and other descriptive information.
Model Version: Each Registered Model has one or more versions. When a new model is added to the Registry, its initial version is 1. After the same name is added to the Registry again, the version number is automatically increased by 1.
Model Stage: For a Registered Model, each Version has a Stage tag. MLflow defines general Stages: Staging, Production, Archived, None, and you can also customize some Stages. Different Stages can be converted.
The usual practice is that those models that are being used will be marked with the Production Stage label. When it needs to be "retired", its Stage is converted to Archive, and the Stage of the new model is set to Production. At the code level, we load the model from the Registry by specifying stage and name of model, so that we can achieve the effect of updating the model only by changing the stage labels of different models.
The application of machine learning models can be divided into two stages: the exploration stage and the productization stage. Both phases come with their own challenges, but PyCaret and MLflow are tools that can help you deal with these issues.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

