














Data strategy
AI in Financial Services - unlocking value in Private Banking and Wealth Management

In AI there’s a term that’s critical: context window. It refers to the limit of information a model can “remember” or process at once. You may have noticed the context window when interacting with artificial intelligence systems: after a while, it starts going rogue — hallucinating, contradicting itself or suggesting things that clash with what it told you just a few lines earlier. When that happens, you’ve hit its context window wall. This is precisely why context engineering — the art of structuring and routing context so models can reason effectively without overloading or drifting — has become more and more discussed in recent months.
Even with today’s larger context windows — and tools like the Knowledge Graph Memory MCP server, mem0, Neo4j or Letta, which are still early attempts at memory — the challenge remains: scaling context without losing control.
In domains like BFSI (banking, financial services and insurance), where precision and auditability matter as much as intelligence, we need compliance-aware orchestration. The way we structure and engineer context will determine how close we can come to producing reliable, regulation-aligned outcomes from a single prompt.
Ask today’s best LLM to walk through a 40-step compliance process; by step 20, it may contradict itself or “forget” prior constraints. That’s the context window wall in action.
Developers patch this today with tricks: chunking long documents into bite-sized pieces, using vector search to pull in relevant snippets or chaining prompts to “remind” the model of earlier steps. These workarounds help, but they’re brittle — one wrong retrieval and the model loses the plot.
Common sense tells us that building an entire app in one prompt is still out of reach — but it’s also the logical horizon of where contextual AI is heading: toward systems that can reason, assemble and refine without human patchwork.
Whether this level of autonomy is achievable — or even desirable — is still an open question. What’s clear, however, is the direction of travel: the path toward it demands that AI systems gain a far deeper grasp of context.
Not just more data, but the right structure of relationships — the ability to trace how a change in one component affects another, maintain dynamic links between data, logic and compliance rules and reshape those connections as situations evolve.
In other words, the AI would need to reason not just about what to build, but how every part fits together — from user intent to regulatory constraint.
This is more than just having context; it’s about having the right parts of the right context at the right time. It should be grounded in solid knowledge but flexible enough to adapt while doing.
By solid knowledge, I mean the verified and traceable facts that don’t shift with every interaction — these are things like regulatory frameworks, validated data models and institutional logic. Flexibility, meanwhile, lies in how these are applied: dynamically recombining them as user intent, data inputs or compliance constraints evolve in real time.
That balance — between stability and adaptability — is the ultimate goal. And as part of our financial services innovation team at Thoughtworks, we’re making significant progress toward it.
Of course, there’s a lot we can do at the level of the prompt — it’s where we can provide context and information to the model. However, this only gets us so far. The more fundamental challenge we face when dealing with particularly complex and multifaceted tasks is the model’s limited capacity to hold and apply complex context over time.
Even a perfect prompt will hit a wall if the model can’t retain what it has already built. Ask it for a stock market analysis app, and at first it scaffolds a few components — but soon it forgets variable names, loses track of dependencies and overwrites its own logic. The architecture collapses under the weight of its forgotten context.
In short, the challenge isn’t more context. It’s better context selection.
In AI terms, bad context is like handing a model every PDF your company has ever produced and expecting a sharp answer. Good context is giving the model only the sections of documents relevant to the question — for example, the policy paragraphs and the latest rate sheet that contain the necessary information — so it can reason effectively without wading through everything. This is where vector search, knowledge graphs and retrieval-augmented generation (RAG) play a role: they filter the haystack so the AI sees only the right needles.
Vector search is great for pulling the closest match, but it can drown in ambiguity — “interest rate” could mean mortgage, deposit or credit card APR. Graphs shine here: they bring structure, connecting rate → product → regulation. And RAG brings it together, helping the model output accurate responses.
In practice, we often blend the three approaches to get the best of each:
Embeddings capture fuzzy meaning: they let the AI understand that “interest rate” in one document can relate to “APR” or “loan rate” in another, even if the wording differs.
Graphs provide hard structure: they encode explicit relationships, connecting a rate to a specific product, regulation or policy, so the AI doesn’t make wild guesses.
RAG (retrieval-augmented generation) ties it all together, allowing the model to generate fluent answers while staying grounded in the selected context.
By combining embeddings for semantic understanding, graphs for precise connections and RAG for coherent reasoning, the AI can answer complex questions efficiently and accurately.
When my son was six, I taught him to skip stones across the water — “hacer patitos,” as we call it in Argentina. As an adult, I can explain the physics behind it: the equation for lift, the role of angular momentum (spin) and the release angle. The more spin, the more skips. Simple, right?
But does a six-year-old need a full scientific breakdown to throw a stone?
If I gave this note to my kid would it have him skipping stones?
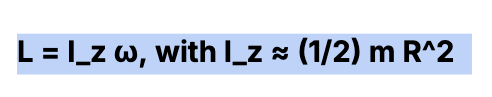
Probably not!
I’m an over-informed kid raising a not-so-over-informed kid (by design), and I know for a fact that if I had started reciting formulas, I would have lost him before the first throw. The explanation had to be practical. Immediate. Something his body could feel before his brain could analyze.
I didn’t have to consciously debate this approach — it’s what many would call common sense. And common sense, in this context, is our brain’s innate capacity to select the right context and adapt to it. It’s the same capacity that stops you from saying something you’ll regret five seconds later.(that, too, is context selection).
So teaching a six-year-old to skip stones didn’t require an abstract, mathematical explanation: it needed one rooted in action and the context of one’s own body:
Keep the stone flat.
Push with your index finger on release.
Let your wrist flick as you throw forward.
And just like that, he got it.
The funny thing? Even a brilliant physicist might miss the first throw while following the above equation if they’ve never done it before. Theory is one thing; applied context is another. Wormholes may be theoretically possible, but has anyone traveled through one?
That’s exactly where AI is right now: it’s not about the amount of context it has. It’s about knowing which context is relevant and how to apply it in the real world. Teaching the technology is similar: we don’t need to overload it with theoretical equations that represent every possible fact. We need to route just enough context at the right time so it “feels” the task and executes — like a child skipping a stone.
If the stone is our raw data, the wrist flick is the context routing that leads to successful task completions — skips across the water.
Of course, AI doesn’t have a body, and it doesn’t literally feel the task. The stone-skipping example is a metaphor: the father is guiding the child, selecting the right practical cues — how to hold the stone, how to flick the wrist — and showing only what’s needed. In the same way, a developer or data engineer selects the right context for an AI, curating data and guidance so the model can reason effectively. The child learns through action; the AI learns through relevant context. The principle is the same: success comes from choosing the right context, not from overloading with every possible detail
Across the industry we’re not just coding apps — we’re building AI systems inspired by the human brain. They aren’t brains themselves, and they don’t think like humans, but their architectures increasingly reflect the brain’s design, allowing them to mimic aspects of human reasoning when given the right context.
For example, the 'Dragon Hatchling' model introduces a biologically inspired network of locally interacting neuron particles, incorporating principles like synaptic plasticity and Hebbian learning. These ideas help AI retain context, form abstractions and reason more effectively — without replicating the brain’s full complexity.
With that in mind, we need to focus on refining how context can be maintained, reshaped and adapted across multiple layers of memory — all while relying on a large, purpose-built knowledge base.
In our case, this is a custom BFSI knowledge base which contains internal policies, regulatory guidelines, product rules and client-related data. Precision, compliance and reliability aren’t optional; they’re the core of the architecture.
It’s worth noting that this knowledge base itself is built with care: information is chunked immediately upon ingestion, then vectorized for semantic retrieval and mapped into graph structures to preserve relationships (e.g., customer → account → transaction → risk rule). This allows the system to achieve an almost exact understanding of semantic intent, not just keyword matching.
But the real leap is in how context is retained and updated. You can think of it as a dual-memory system:
Long-term memory — the structured knowledge base described above, which is persistent and ever-expanding.
Short-term or residual memory — a dynamic session layer, almost microservice-like, that manages the user’s profile, query history, evolving intent and the current conversational thread.
This dual structure ensures that every interaction isn’t just a one-off query, but part of a continuous, adaptive reasoning process.
In BFSI, where a hallucinated answer could lead to regulatory risk, combining long-term knowledge with session-aware context is central to improving precision and traceability. While this approach does not eliminate hallucinations — which are inherent to large language models — it provides a structured framework that makes them less likely and more controllable. The goal of our team at Thoughtworks is to explore and refine these methods so that AI outputs align more reliably with the underlying data and regulations, even as the technology continues to evolve.
Ingestion and chunking → Breaks raw documents into meaningful, retrievable units.
Vectorization → Encodes chunks into embeddings for semantic intent matching.
Graphing → Maps relationships (customer → account → transaction → compliance rule).
Long-term memory → Persists structured knowledge for precision and depth.
Short-term/session memory → Tracks user profile, query history and evolving intent, as well as current conversational context.
Context assembly → Orchestrates the right mix of everything mentioned above: the most relevant chunks, embeddings, graph connections and session information, prioritizing compliance and data relevance, to construct the context for the model.
LLM Generation → Provides the curated context to the model for precise and traceable answers.
It takes the human brain roughly 18 to 25 years to develop the neural connections needed to process information efficiently. In AI terms, our models are still in their formative years, learning how to manage and prioritize context.
Just as a teenage brain rewires itself to make better decisions, an AI system must reorganize its memory and retrieval pathways to handle information flexibly and reliably. Human memory itself is constructive — we constantly rebuild narratives from facts and interpretations — which is a reminder that context, not raw data, drives understanding.
Translating this to AI, the challenge is building hybrid memory systems where long-term and short-term layers work in tandem: vector stores capture semantic intent, graph structures preserve relationships and compliance paths, and orchestration layers dynamically select the most relevant context. The difference is clear: a system that merely recalls information sounds fluent, but one that adapts context continuously can serve customers accurately and withstand audit scrutiny.
We might even say that this rewiring can only be done through context engineering: this somewhat nascent discipline or approach represents and will enable an evolution from information to actionable, context-driven reasoning.
Imagine a financial advisor needing a portfolio simulator that factors in ESG preferences, tax law and current rates. Building this reliably requires careful coordination of data, rules and context.
This is why context engineering and context routing is vital: selecting the right pieces of information, in the right sequence, is challenging but essential for accuracy and compliance. At Thoughtworks, we have the expertise to design systems that manage these complexities effectively, ensuring context is applied correctly across multiple layers of memory and logic
We’re gradually approaching a point where a single, well-curated prompt can guide complex workflows more efficiently than ever before. While humans will still need to define rules, ensure compliance and validate outcomes, the right context routing can significantly reduce manual overhead and accelerate innovation. It’s not magic — it’s the careful orchestration of information, context and logic.
And just like teaching a child to skip stones, context engineering takes patience, iteration and careful guidance. Until then, I’ll be here, throwing stones across the water, helping AI learn to skip.
An earlier version of this essay was published on Matt Kamelman’s blog.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

