














Cloud
Using Pipelines to Manage Environments with Infrastructure as Code


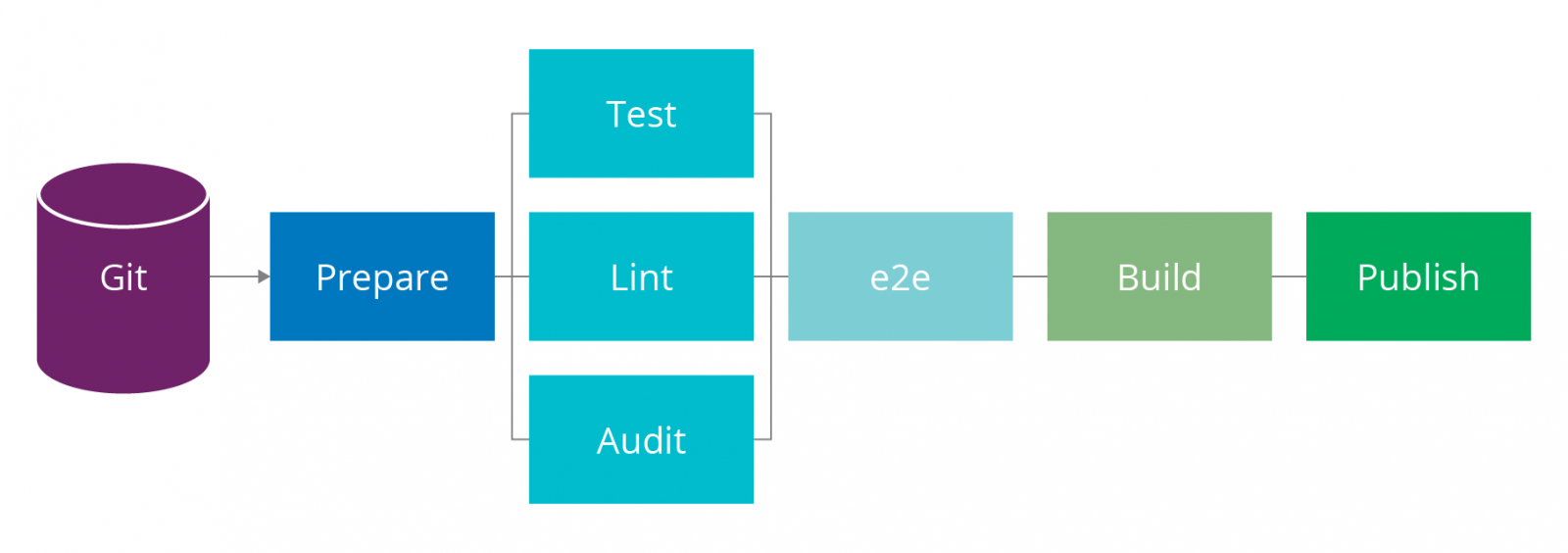
- aggregate:
- put: dev-container
params:
<< : *docker-params
build: git
dockerfile: git/Dockerfile.build
- put: serverspec-container
params:
<< : *docker-params
build: git/serverspec
dockerfile: git/serverspec/Dockerfile.serverspec
FROM node:10.11-stretch
ENV CONCOURSE_SHA1='f397d4f516c0bd7e1c854ff6ea6d0b5bf9683750'
CONCOURSE_VERSION='3.14.1'
HADOLINT_VERSION='v1.10.4'
HADOLINT_SHA256='66815d142f0ed9b0ea1120e6d27142283116bf26'
SHELL ["/bin/bash", "-o", "pipefail", "-c"]
RUN apt-get update &&
apt-get -y install --no-install-recommends sudo curl shellcheck &&
curl -Lk "https://github.com/concourse/concourse/releases/download/v${CONCOURSE_VERSION}/fly_linux_amd64" -o /usr/bin/fly &&
echo "${CONCOURSE_SHA1} /usr/bin/fly" | sha1sum -c - &&
chmod +x /usr/bin/fly &&
curl -Lk "https://github.com/hadolint/hadolint/releases/download/${HADOLINT_VERSION}/hadolint-Linux-x86_64" -o /usr/bin/hadolint &&
echo "${HADOLINT_SHA256} /usr/bin/hadolint" | sha1sum -c - &&
chmod +x /usr/bin/hadolint &&
apt-get clean &&
rm -rf /var/lib/apt/lists/*
require_relative 'spec_helper'
describe 'dev-container' do
describe 'node' do
describe file('/usr/local/bin/node') do
it { is_expected.to be_executable }
end
[
[:node, /10.4.1/],
[:npm, /6.1.0/]
].each do |executable, version|
describe command("#{executable} -v") do
its(:stdout) { is_expected.to match(version) }
end
end
describe command('npm doctor') do
its(:exit_status) { is_expected.to eq 0 }
end
end
describe 'shell' do
%i[shellcheck].each do |executable|
describe file("/usr/bin/#{executable}") do
it { is_expected.to be_executable }
end
end
end
end
platform: linux inputs: - name: git run: path: bash dir: git/serverspec args: - -c - ./entrypoint.sh ./run
platform: linux
inputs:
- name: git
caches:
- path: git/node_modules
run:
path: sh
dir: git
args:
- -exc
- |
npm i
./go linter-${TARGET} - task: lint-sh
image: dev-container
params:
<< : *common-params
TARGET: sh
file: git/pipeline/tasks/linter.yml



Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

