













Agile engineering practices
Enabling evolutionary database development: Database branching with Lakebase

Most enterprise AI projects fail not because the model is bad, but because organizations struggle to measure whether the system is actually working. While advances in foundation models have lowered the barrier to building AI applications, moving from a prototype to a reliable enterprise-grade deployment remains difficult.
Based on a study by MIT last year, around 95% of AI projects fail. The challenge is rarely model capability alone. Instead, organizations face two persistent obstacles: defining success in a probabilistic environment and navigating a rapidly expanding ecosystem of evaluation tools and frameworks.
Unlike traditional software, AI systems don’t always produce the same output for the same input. Success is often subjective, context-dependent and influenced by multiple components, including prompts, retrieval systems, business rules and agents. As a result, evaluation has become one of the most important and most misunderstood disciplines in enterprise AI adoption.
This article explores a practical framework for evaluating conversational AI agents, covering everything from unit evaluations and persona-based testing to production observability and continuous improvement.
Traditional software testing assumes deterministic behavior: the same input produces the same output every time. Conversational AI systems operate differently. Multiple responses may be valid, outcomes often depend on context and applications increasingly combine prompts, retrieval systems, business rules and agents. As a result, evaluation must move beyond exact-match assertions and focus on outcomes such as correctness, relevance, task completion and user satisfaction.
Traditional applications rely on explicit business logic, where predictable inputs produce predictable outputs. This makes testing straightforward because expected outcomes can be defined in advance. LLM-based applications, however, are different: trained on massive text corpora across sources like books and Wikipedia, they generate responses probabilistically, choosing each next token based on likelihood rather than fixed rules.
For instance, when asked “Who’s an astronaut?”, the model may assign varying probabilities to possible next words, leading to different but valid responses.
Who’s an astronaut?
“An astronaut is a …”
Word | Probability |
person | 0.42 |
trained | 0.18 |
professional | 0.15 |
space | 0.07 |
someone | 0.06 |
Possible Responses:
“An astronaut is a person trained to travel in space.”
“An astronaut is a trained professional who participates in space missions.”
“An astronaut is someone who travels into space.”
Not every enterprise AI application is a multi-agent system. Many are still implemented as single-agent workflows or RAG pipelines. However, as systems become more sophisticated, multiple collaborating agents are becoming increasingly common. This article focuses on using LLM‑driven chat interfaces as replacements for traditional business rule engines.
In practice, the LLM layer is rarely a single interaction; instead, it constitutes a mesh of specialized agents collaborating to optimize outcomes. This ecosystem is a mix of deterministic agents, which return structured, predictable outputs like booleans, and non-deterministic agents that produce natural language responses.
Deterministic agent: e.g. intent identification agent or a guardrail agent.
Non-deterministic agent: e.g. summarization agent, rewriting agent.
A common oversight in AI architecture is treating RAG-based and pure prompt-based applications as interchangeable. While both leverage LLMs, their operational objectives and the subsequent testing required are distinct.
RAG-based systems: These function as a bridge to an organization’s proprietary and trusted data. The LLM acts as a sophisticated reasoning layer that synthesizes information retrieved from a trusted, internal knowledge base to ensure accuracy and 'grounding.'
Pure prompt-based systems: These rely on 'in-context learning,' where extensive system prompts provide the model with the necessary logic and detail to execute specific tasks. Here, the LLM usually is the primary engine for both knowledge and processing.
Considering both of these applications have a different intent, our testing approach should also be calibrated accordingly.
RAG systems are typically evaluated on:
Retrieval relevance
Context coverage
Faithfulness
Hallucination rates
Prompt-based systems are typically evaluated on:
Instruction adherence
Task completion
Reasoning quality
Output consistency
At Thoughtworks, we advocate for shifting testing left: validating early and often to build inherent trust in the application. In this same spirit, the evaluation strategy for LLM-based systems must evolve alongside the product as it moves from Dev to SIT, UAT and production.
A critical component of this journey is the user persona. Since LLM applications are probabilistic by nature, their performance is highly sensitive to the diversity of user interactions. Early in dev and SIT, we rely on synthetic personas to simulate behavior; during UAT, these are refined by actual business users. Finally, in production, real-world monitoring allows us to continuously evolve these personas based on authentic user intent.
By analyzing the drivers listed above, we can identify the core ingredients necessary to build a trustworthy LLM chat evaluation framework. I have categorized them into the following functional groups.
Business context: Most AI chat agents aren’t merely RAG implementations; they are primarily defined by complex business contexts, with RAG serving as a supporting feature. For instance, the conversational journey of an AI coach is fundamentally different from that of a banking assistant. Consequently, any robust evaluation framework must prioritize this contextual intent as a core metric.
Evaluation should scale with the maturity of the application: The evaluation framework must be architected to evolve seamlessly from dev to production. It should scale from rapid, synthetic testing in development to stakeholder-validated personas in UAT and real-world monitoring in live environments. This lifecycle-driven approach ensures our "ingredients" for trust remain relevant as the application matures and user complexity grows.
Handling variations in user phrasing: The framework must account for semantic variance, where users express the same intent through different phrasing or fragments. Whether a query is a full question ("Who is an astronaut?") or a simple keyword ("Astronauts"), the system must maintain consistent accuracy. Validating this linguistic flexibility ensures a stable user experience regardless of how a person chooses to communicate.
Personalization and contextual relevance: The framework must evaluate how user context, including profiles, history and preferences, shapes each response. Validating these signals ensures the model delivers a tailored, consistent experience that evolves with the user's journey.
Probabilistic output stability: Responses may vary across identical inputs. Evaluation should therefore focus on consistency of outcomes, factual accuracy and adherence to expected behavior rather than exact output matching.
Agent and model: Evaluation should provide visibility into the performance, cost and quality trade-offs of individual agents and models, enabling informed architectural decisions.
In my experience building and scaling agentic systems, I’ve found that effective evaluation must be addressed across three distinct layers:
Persona-based testing: High-fidelity, multi-turn simulations. We test against "human personas" to validate the agent’s logic and conversational flow in real-world scenarios.

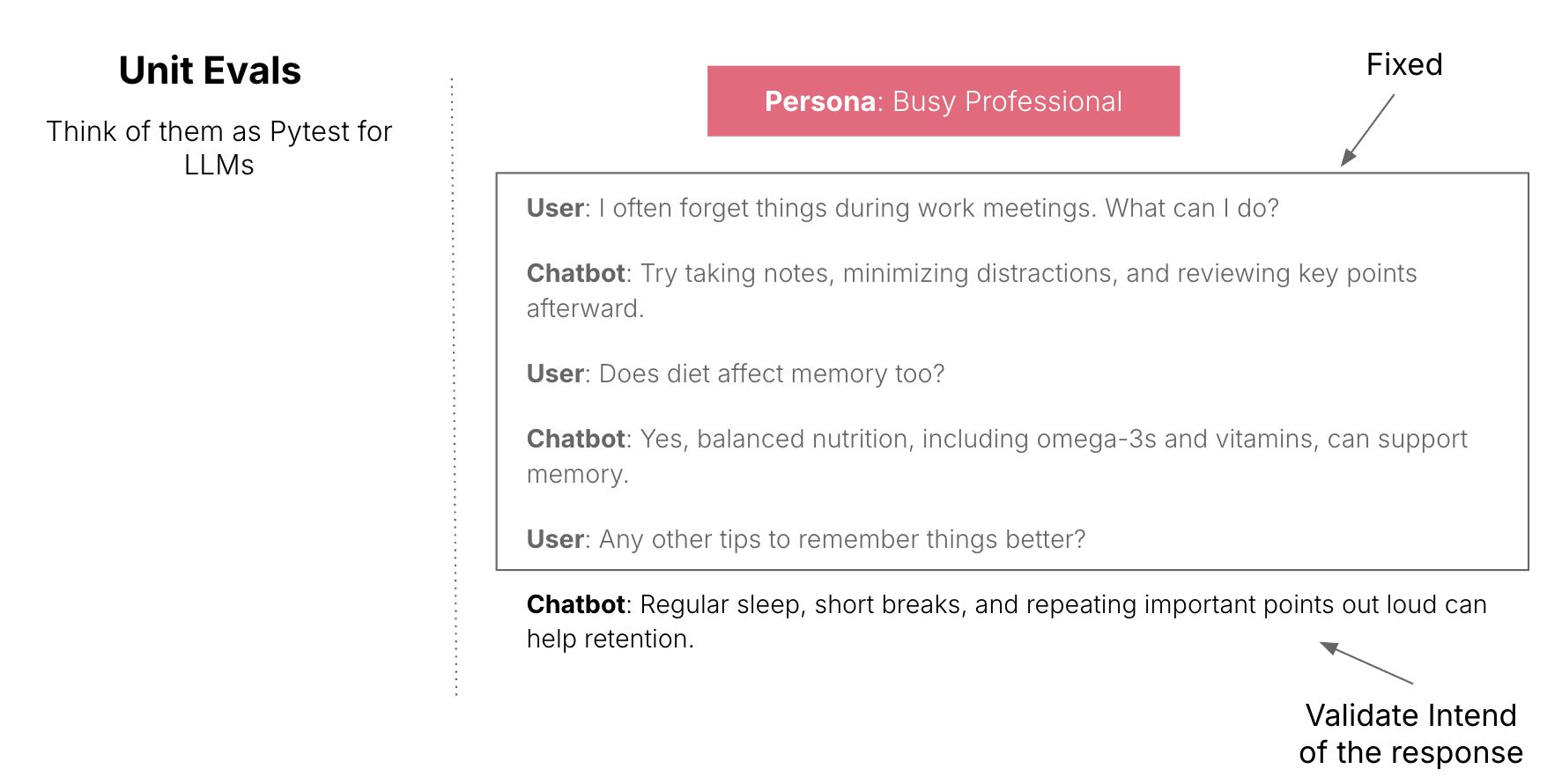
Functional unit evals: The "Pytest" for LLMs. These are automated, assertion-based checks that catch regressions in the model’s core reasoning and output format. I further categorize unit evaluations into two groups based on the dimensions in which this unit is identified:
Agents as a unit: Here, individual agents are unit tested to verify that they produce intended outcomes.
Conversation as a unit: Conversation-level evaluations treat a complete interaction as the unit under test. Rather than comparing responses using exact matches, evaluators assess whether the conversation achieved the intended outcome while maintaining accuracy, consistency and user satisfaction.
Operational observability: The production safety net. Real-time tracing and monitoring to bridge the gap between "it works on my machine" and "it works for the user."
Below are some of the examples of tools in each of the categories:
| Persona-based | Unit evals | Observability |
| Snowglobe | DeepEval | LangSmith |
| Collinear | ragas | Langfuse |
| Rhesis | TruLens | Helicone |
I’ve observed that without a clear understanding of these categories, teams often end up forcing a use case into the wrong evaluation tool. This 'square peg in a round hole' approach results in a fragmented mess. Instead of a cohesive system, you get an inextensible architecture where your testing and monitoring are awkwardly baked into the logic, making it nearly impossible to scale or pivot.
Step 1: Start with unit testing and early persona-based testing setup.
As you start developing your application, it’s crucial to begin with unit evaluations for your agents early. This often involves building a “jury” of judges to evaluate system behavior. As you gain deeper insights into your target audience and specific use cases, start building representative multi-turn test scenarios to validate your system through simulated conversations. At this stage, you’ll likely have around 20% of your scenarios automated, with the remaining 80% still requiring manual validation.
Step 2: Refine your personas, judges and tests as your application goes through business user testing.
As you come to the stage where the business users begin testing your conversational AI application, use:
Conversational scenarios to add scenarios to your test suite.
Refine your personas to reflect the personas the users testing with.
Recalibrate the jury of judges to find out the kind of issues which were identified by business users.
With this, you should be able to increase automated test coverage substantially from the earlier ~20%.
Step 3: Introduce production observability.
Once the application reaches production, evaluation should move beyond synthetic testing and into real-world monitoring. Capture traces, user feedback, latency, costs, retrieval quality and failure patterns. Production observability helps identify issues that were never represented in test datasets and provides the feedback loop needed for continuous improvement.
Step 4: Continuously improve using production feedback.
Evaluation frameworks should evolve alongside the application. Review production conversations regularly, identify failure modes, update test datasets and recalibrate LLM judges. The goal isn’t to achieve a perfect evaluation framework on day one, but to continuously increase confidence as the system matures.
Measure core quality in a controlled environment before release:
Accuracy/exact match: How often the output matches expected answers.
Semantic correctness: Meaningfully correct even if wording differs.
Pass rate: The percentage of responses meeting defined success criteria.
Measure real-world performance with actual users along with passing the real conversations through your evaluation tools at a fixed frequency:
User satisfaction: Explicit feedback.
Task success rate: Whether users achieve their goal.
Engagement metrics: Follow-ups, clicks, continued usage.
Latency and response time: The speed of response.
Cost per request: Efficiency of the system at scale.
LLM judges should be periodically calibrated against human-reviewed examples to ensure evaluation quality remains aligned with business expectations. Use LLMs to automate scalable, human-like evaluation:
Helpfulness/relevance. Does the answer address the query?
Coherence and fluency. Is the response clear and well-structured?
Instruction adherence. Did it follow the prompt correctly?
Overall quality score. Rubric-based holistic scoring.
Ensure responses are grounded in retrieved knowledge:
Context relevance. Are the retrieved documents useful?
Faithfulness. Is the answer supported by the context?
Answer correctness. Alignment with ground truth.
Hallucination rate. Frequency of unsupported claims.
Recall@K. How often the retrieval system surfaces the necessary information within its top K results.
For agentic systems, evaluating the final response alone is often insufficient. Additional metrics may include:
Tool selection accuracy
Task completion rate
Planning quality
Failure recovery
Multi-agent coordination
There’s no single metric or tool that can fully evaluate an AI application. Effective evaluation requires a combination of unit testing, persona-based simulations and production observability that evolves alongside the application lifecycle. Organizations that treat evaluation as a continuous discipline, rather than a one-time testing activity, will be far better positioned to build trustworthy AI systems at scale.


