














Generative AI
AI evals for MCP in AIOps

Knowledge-driven conversational solutions are essential in modern digital workflows. They allow large language models to interact with curated knowledge bases for a diverse range of tasks including customer support, search and analytics. However, evaluating them poses some challenges — they’re typically composed of multiple interdependent components, continuously evolving sources of data and feature opaque, black box mechanisms.
In this post, we detail how we evaluated an enterprise AI conversational system powered by AWS Bedrock Agents and Amazon Kendra, using Weights & Biases (W&B) Weave.
Before this, our evaluation relied on ad hoc manual testing. Team members submitted queries to the system, manually inspected the generated responses, and subjectively judged quality. This approach was inconsistent across evaluators, couldn't scale as the knowledge base grew, lacked reproducibility and provided no way to isolate whether failures originated from retrieval, prompting, or generation.
By replacing this fragmented process with a structured, metrics-driven evaluation framework, we achieved significant improvements in system performance, accuracy and stakeholder alignment.
Although traditional metrics like accuracy or F1 score are applicable to algorithmically-generated text data, they’re insufficient for assessing a complex conversational system. This isn't because we can't calculate precision/recall for text, but because binary classifications miss the multiple dimensions of retrieval systems. Our evaluation identified several critical challenges:
Black-box evaluation limitations. Bedrock Agents concealed retrieval mechanisms, which made it difficult to directly calculate retrieval metrics.
Inconsistent source attribution. Generated responses were often missing citations linked to knowledge base documents.
An evolving knowledge base. As the knowledge base expanded from object storage to enterprise search, the evaluation criteria needed to evolve.
Multi-stakeholder alignment. Business users, technical teams and compliance officers all required different evaluation perspectives.
In most established forms of machine learning, accuracy is typically a single measure of correct predictions. However, for knowledge-driven conversational solutions, accuracy is multi-dimensional; it needs to be assessed across three interdependent components:
A retrieval component (RAG): Did the system retrieve relevant and correct documents based on the input query?
A prompt engineering component: Did the system effectively guide the LLM to use retrieved context?
Language model component (the LLM): Did the LLM generate a factually correct and coherent answer?
All three need to work in harmony for accuracy. Perfect retrieval with poor prompting, for example, still produces irrelevant answers, while strong prompting with bad retrieval leads to hallucinations.
To address these challenges, we implemented Weights & Biases Weave as a unified evaluation platform. The system under evaluation is a customer-facing conversational AI assistant: users submit natural language queries, Amazon Kendra retrieves relevant documents from a knowledge base and AWS Bedrock Agents generates a response using those documents as context.
Because failures can occur at any stage of this pipeline — wrong documents retrieved, poor prompt construction, or unfaithful generation — a single accuracy score isn’t sufficient. Our framework consolidated assessment across five critical dimensions: retrieval quality, answer faithfulness, answer relevance, context precision and system performance. Each dimension targets a specific stage of the pipeline, enabling us to pinpoint exactly where quality degrades.
The components of the solution included:
A unified evaluation project: Using W&B Weave's project structure, we centralized all test cases, metrics and production data in a single workspace — ensuring every team member worked from the same source of truth.
A structured test dataset: We curated a set of representative queries, each paired with ground truth answers and expected source documents, to measure system performance consistently across iterations.
Multi-dimensional scoring: More than 25 granular metrics were implemented, including precision@k, recall@k, semantic similarity and hallucination detection — each targeting a specific stage of the RAG pipeline.
Traceability: Each evaluation run captured full traces of prompts, retrieved documents and generated responses. This made it possible to debug failures at any stage.
Visualization: Custom dashboards provided actionable insights for both technical teams (who needed component-level diagnostics) and business stakeholders (who needed system-level quality trends).
We developed a systematic analysis and improvement workflow, which enabled consistent progress tracking and targeted enhancements.
Our initial evaluation runs provided a strong starting point across multiple dimensions:
The overall RAG score was 0.8626, providing a reliable benchmark for system performance.
Answer similarity began at 0.4444, reflecting early alignment with ground truth answers.
Topic coverage was 0.6667, showing partial but consistent coverage of expected topics.
Response confidence started at 0.85, representing a solid foundation for reliable responses.
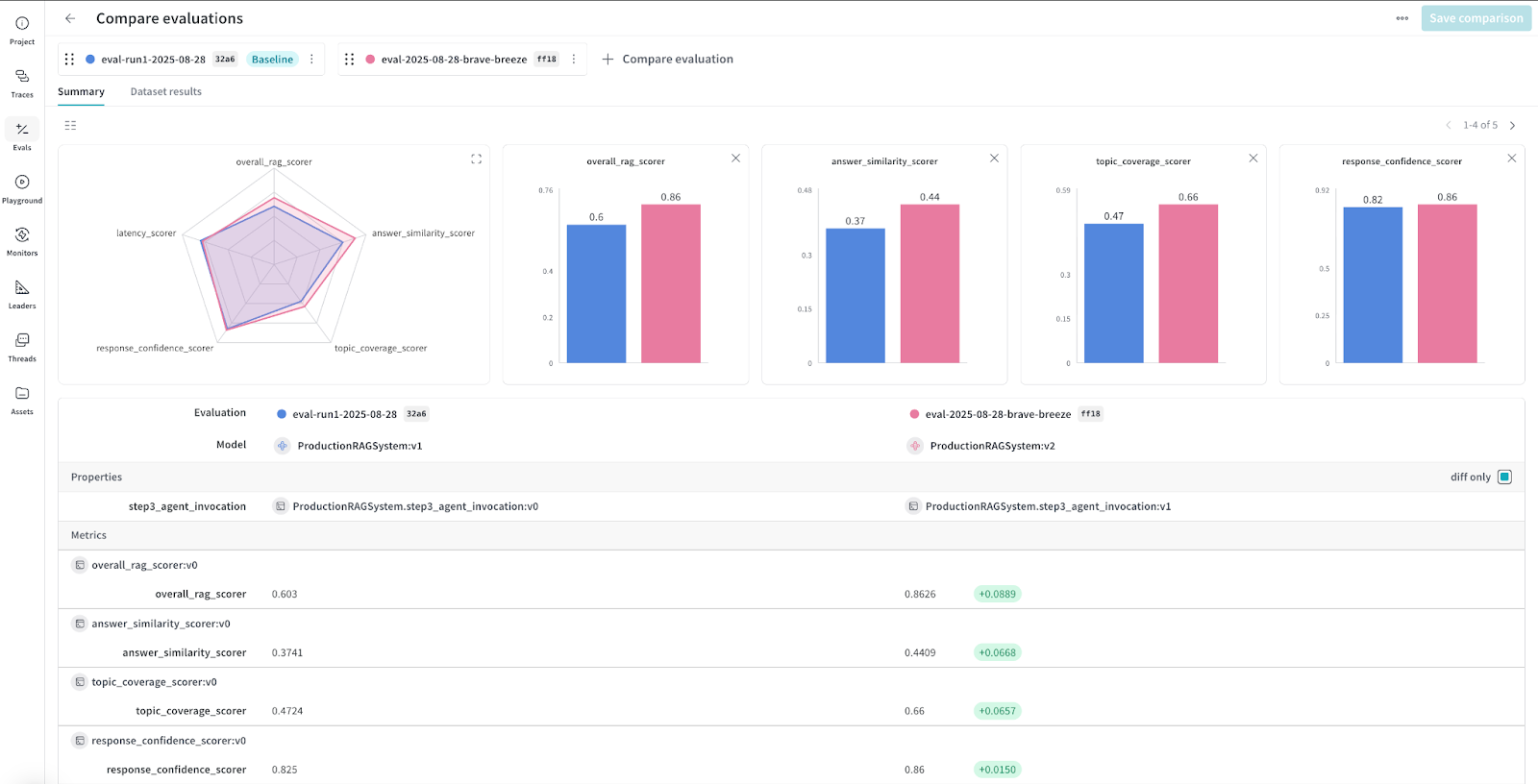
Figure 1: W&B dashboard showing initial baseline metrics across all evaluation dimensions.
To gain a detailed understanding of system performance, we evaluated individual components — document retrieval, prompt engineering and language model generation — using targeted metrics.
The retrieval component (Amazon Kendra) is responsible for finding relevant documents from the knowledge base. If it fails, returning irrelevant or incomplete documents, the LLM cannot produce a correct answer regardless of prompt quality.
We measured:
Retrieval precision: The percentage of relevant documents among retrieved ones improved from 0.65 to 0.82 (+26%).
Retrieval recall: Relevant documents successfully retrieved increased from 0.58 to 0.79 (+36%).
Context relevance: Semantic alignment between query and retrieved documents rose from 0.72 to 0.88 (+22%).
Information coverage: The completeness of retrieved information grew from 0.56 to 0.91 (+63%).
The prompt engineering component determines how effectively retrieved context is presented to the LLM. Poor prompts can cause the model to ignore relevant context or produce badly formatted responses.
Instruction following: Adherence to prompt instructions improved from 0.79 to 0.93 (+18%).
Context utilization: Effective use of retrieved context increased from 0.61 to 0.84 (+38%).
Format adherence: Consistency with requested response format improved from 0.88 to 0.97 (+10%).
Prompt robustness: Stability across input variations rose from 0.70 to 0.89 (+27%).
The generation component is where the LLM produces the final response. We measured whether outputs were factually grounded in the retrieved documents and complete.
Factual accuracy: The correctness of generated responses increased from 0.73 to 0.88 (+21%). We used a threshold-based embedding similarity approach (responses with >0.8 similarity to ground truth deemed correct) combined with rule-based factual verification against knowledge sources.
Hallucination rate: Unsupported content generation decreased significantly from 0.18 to 0.04 (–78%).
Answer coherence: Logical flow and readability improved from 0.85 to 0.92 (+8%).
Response completeness: Coverage of all query parts rose from 0.67 to 0.91 (+36%).
Source attribution is critical for enterprise trust. Users need to verify where answers come from. We measured whether responses properly cited the knowledge base documents they drew from.
Citation presence: The percentage of claims with supporting citations increased from 45% to 87% (+93%)
Citation accuracy: The correctness of source references improved from 62% to 91% (+47%)
Attribution completeness: The percentage of retrieved documents correctly cited rose from 39% to 82% (+110%)
The component-level metrics above helped us pinpoint where in the pipeline problems occurred. For example, low retrieval recall meant the LLM never saw the right documents, while low context utilization pointed to a prompting issue. However, we also needed to measure how the system performed end-to-end from the user's perspective, since users don't distinguish between retrieval failures and generation failures — they simply see a bad answer.
We therefore tracked four system-wide metrics that capture overall answer quality:
Metric category | Initial score | Final score | Improvement | Measures taken |
Overall RAG score | 0.8626 | 0.9404 | +9% | Holistic improvements across all dimensions |
Answer similarity | 0.4444 | 0.8333 | +87.5% | Enhanced semantic matching techniques |
Topic coverage | 0.6667 | 1.0 | +50% | Knowledge base alignment and query expansion |
Response confidence | 0.85 | 0.95 | +12% | Source attribution reinforcement |
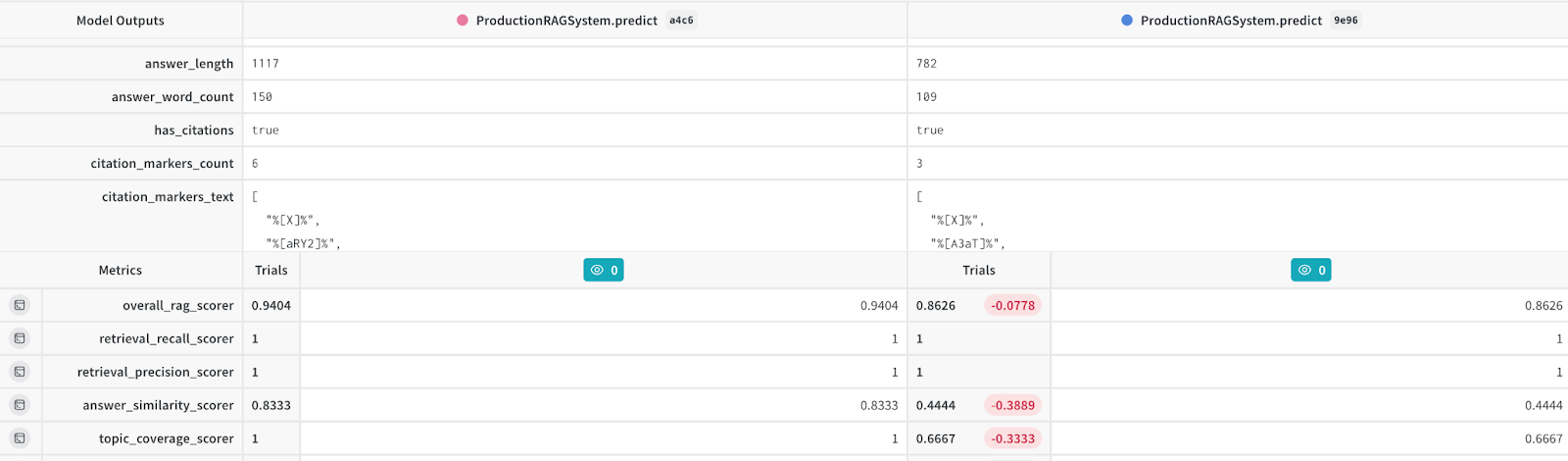
Figure 2: W&B trace comparison view showing before/after analysis of the same query.
To be clear, the evaluation framework didn’t improve the system by itself; it provided the diagnostic visibility needed to identify specific weaknesses. We then followed an iterative cycle: evaluate the system using W&B Weave, identify the lowest-performing metrics, implement a targeted fix and then re-evaluate to measure impact.
Below are the specific interventions we made and their results.
Our initial evaluation used token-based matching to measure how closely system responses matched ground truth answers. However, this penalized semantically correct responses that used different wording — creating false negatives that obscured the system's true performance. We replaced this with embedding-based similarity, which compares meaning rather than exact words.
This was important because once our scoring accurately recognized semantically equivalent answers, we were able to trust the metrics to guide real improvements rather than chasing false negatives.
Example:
Before: The system answered “The product is available” for a query where the ground truth was “The product is in stock.” Token-based matching scored this poorly despite identical meaning.
After: Embedding-based similarity correctly scored this as a strong match. This recalibrated our baseline and let us focus optimization on areas with genuinely low scores.
Our evaluation revealed that the system only covered 66.7% of expected topics in its responses. There were two root causes: (1) user queries used different terminology than the knowledge base documents, which caused retrieval misses, and (2) some documents weren’t properly indexed by Kendra.
We addressed the first with query expansion — automatically augmenting user queries with synonyms and related terms so that retrieval could match documents even when wording differed. For the second, we performed a knowledge base indexing audit, verifying that all relevant documents were indexed and discoverable by Kendra. Together, these interventions improved topic coverage from 0.6667 to 1.0 (+50%).
Example:
Previously, a query about “return policy for defective electronics” failed to retrieve relevant documents because the knowledge base used the term “warranty claims for faulty devices.” After query expansion, the system matched the correct policy documents covering all scenarios.
Improvements in source attribution and confidence scoring mechanisms increased response confidence by 12%.
Example:
Now, responses include citation links to knowledge base documents along with confidence scores, such as "Product specs validated with KB Doc ID 12345, Confidence: 0.92."
We implemented rule-based factual verification that extracts structured claims from responses and validates them against our knowledge base.
Example:
A response stating "Supports up to 16 GB RAM" was validated by matching the triple (Product X, supports, 16 GB RAM) to the knowledge base, eliminating hallucinations.
Holistic adjustments to retrieval and generation configurations resulted in a 9% performance improvement.
Example:
By fine-tuning retrieval thresholds, a query for "latest software updates" now retrieves up-to-date documents, improving relevance.
These targeted interventions allowed us to systematically address bottlenecks, improving the quality and reliability of the RAG-based system without manual guesswork.
To streamline evaluation of the retrieval system powered by AWS Bedrock Agents and Amazon Kendra, we integrated the evaluation pipeline with Weights & Biases (W&B). This allowed us to automatically track evaluation configurations, test inputs, outputs, and granular metrics in a consistent, transparent, and reproducible way.
A key practical advantage is that this integration required minimal code changes to our existing AWS pipeline. By "patching" the Bedrock client, W&B Weave automatically captures every LLM call — including the prompt, model parameters and response — as a traced event.
The following snippet shows the core pattern:
import weave
import boto3
from weave.integrations.bedrock.bedrock_sdk import patch_client
# Initialize W&B Weave tracing
weave.init("rag-evaluation-project")
# Patch the Bedrock client so all LLM calls are automatically traced
bedrock_client = boto3.client("bedrock-runtime")
patch_client(bedrock_client)
# Kendra client for document retrieval
kendra_client = boto3.client("kendra")This automatic tracing eliminated manual logging and ensured every evaluation run was fully reproducible — any team member could inspect what happened at each step of the pipeline for any past evaluation.
This integration provided several important benefits, including:
Faster deployment and reduced setup time.
Standardized metrics which enabled consistent evaluation across test cases.
Full traceability of evaluation runs for auditing.
Cross-team visibility: Interactive W&B dashboards offered clear insights for both technical and business stakeholders.
Our approach transformed the evaluation of a complex RAG-based AI system from ad hoc, manual inspection into a systematic, metrics-driven, and reproducible process.
By analyzing retrieval, prompt engineering and language model components in a unified framework, we gained clear visibility into system performance and identified actionable improvement areas.
Integrating structured evaluation practices with W&B Weave enabled faster iteration cycles, traceable decision-making, and alignment across technical and business teams. This approach ensured more reliable and complete responses, reduced need for manual review, and strengthened stakeholder confidence in deploying enterprise AI solutions.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

