














Observability
Reliability under abnormal conditions — Part One

We would hold production traffic in our queues for a certain amount of time, typically 6-8 hours (enough to create necessary queue depth for a load test), release it and then monitor application behavior. We built a business impact dashboard to monitor business facing metrics. We took utmost care to not affect business SLAs when doing so. For example, for our order routing system, we would not hold expedited shipping orders as it would affect the shipping SLAs. Also, we had to be aware of downstream implications of the test — essentially we were load testing the downstream systems as well. So in our case, it would be the warehouses that would receive a lot of requests for shipments at the same time. This would put pressure not only on their software systems but also their human systems like the workforce in the warehouse.

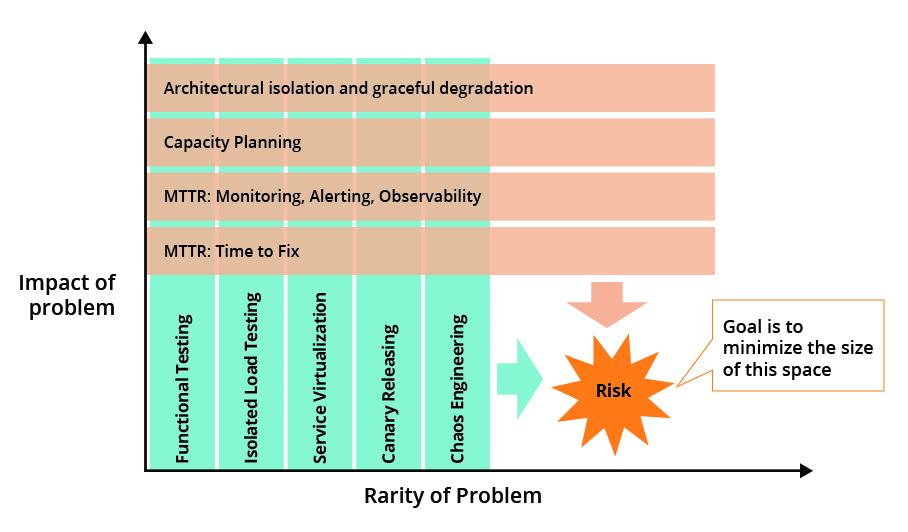

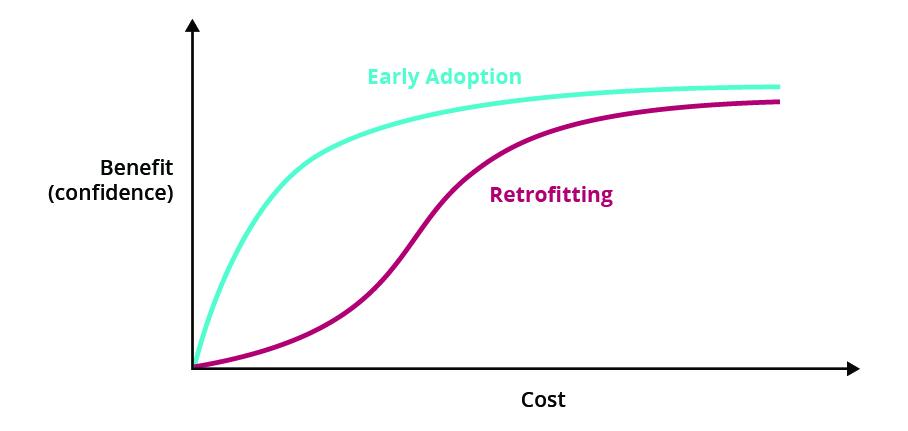
For this reason, we recommend starting as many practices (load testing, observability, chaos engineering, etc) as early as possible to avoid the high cost associated with retrofitting a practice or test suite.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

