














AI and ML
Effective machine learning: Shifting quality left (Part II)

In Part I of our Effective Machine Learning (ML) series, we wrote about the common traps that organizations fall into when delivering ML products, and in Part II, we shared principles and engineering practices to shorten feedback loops. In this post, we’ll share processes and structures that teams can use to reduce friction and optimize the flow of value to their users.
Across Thoughtworks’ collective experience on various data and ML projects, a common theme we see time after time is the notion that software product delivery practices are equally, if not more, important when it comes to building ML products. Even if we have the right ML and engineering practices and technologies in place, we can fail in delivering a successful product if we fail to implement processes that facilitate the flow of information, both within an organization and from our users. So, let’s dive in.
It’s common to see two types of team topologies, both of which are extreme and not always ideal for the flow of value:
Complicated subsystem teams, sliced horizontally by function: For example a data science team, an API team or an MLOps team. In this scenario, it’s common to see backlog coupling, where a team needs to depend on (i.e. be blocked by) another team in order to release a change to production. In one informal analysis, backlog coupling increased the time to complete a task by an average of 10 to 12 times.
Stream-aligned but siloed teams: On the one hand, this team shape is better than the first because teams are cross-functional and empowered with a diverse set of context and capabilities (e.g., product, machine learning, engineering and quality assurance) to autonomously deliver features to users with minimal backlog coupling. However, without intentional connection and alignment between these cross-functional teams, silos naturally emerge and we find teams wasting effort in re-work and solving customer, business or technology problems that have been solved before.
There is no one-size-fits-all team shape and interaction modes will also vary as products and teams evolve. The right team shape for your organization depends on many factors. If you are delivering ML-enabled products, we recommend putting product front and center by creating stream-aligned, cross-functional product teams. To reduce silos, it helps to set up cross-team interaction points (e.g. a community of practice) as a way to reduce the friction of collaboration and to mitigate Conway’s Law.
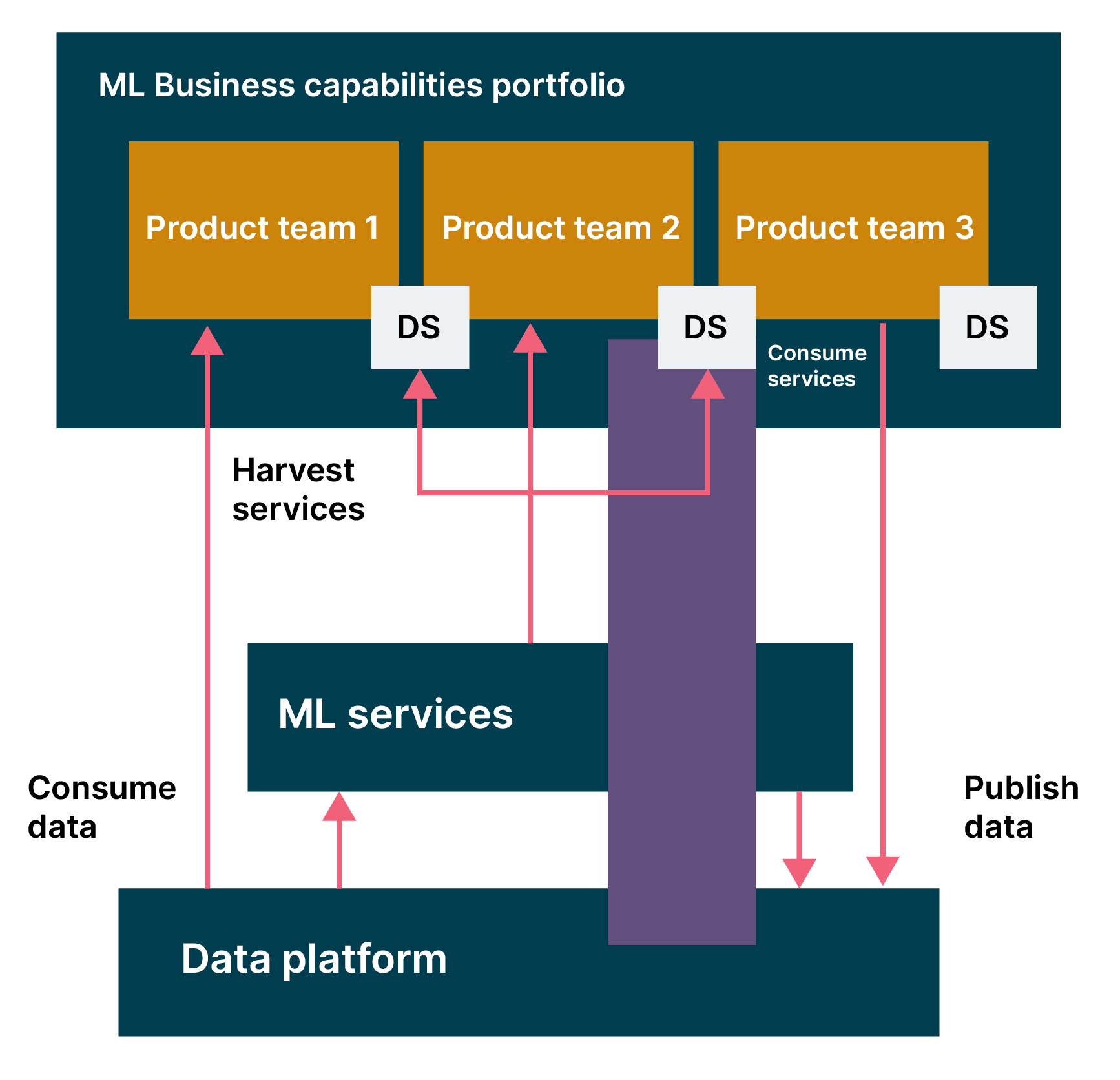
Another common pitfall is the horizontal slicing of work, where we sequentially deliver functional layers of a technical solution (e.g., data lake, data warehouse, data discovery portals, machine learning) from the bottom-up. The downside of this approach is that users can only experience the system and provide valuable feedback after months of significant engineering investment. In addition, horizontal slicing naturally leads to late integration issues when each slice eventually comes together; this increases the risk of releases being delayed.
To mitigate this, we can slice work and stories vertically. This will ensure that:
At the level of stories, we articulate and demonstrate business value in all stories.
At the level of iterations, we regularly demonstrate value to users when we deliver a collection of vertically sliced stories within a reasonable timeframe.
At the level of releases, we plan, sequence and prioritize a collection of stories that’s oriented towards creating business value.
Lean is about focusing on value, optimizing the flow of value and continuous improvement. Lean steers us towards things that create value, whether they come in the form of product features or engineering enhancements that accelerate delivery.
Without setting up feedback loops with users — before, during and after delivery — we might find ourselves investing effort in building a feature, only to find that it doesn’t solve the right problem, or it complicates the codebase without adding business value.
Lean delivery has revolutionized the manufacturing industry and the software industry, and ML is no exception. Teams can ensure their efforts lead to valuable outcomes by adopting Lean delivery principles; this is especially important in the context of machine learning.
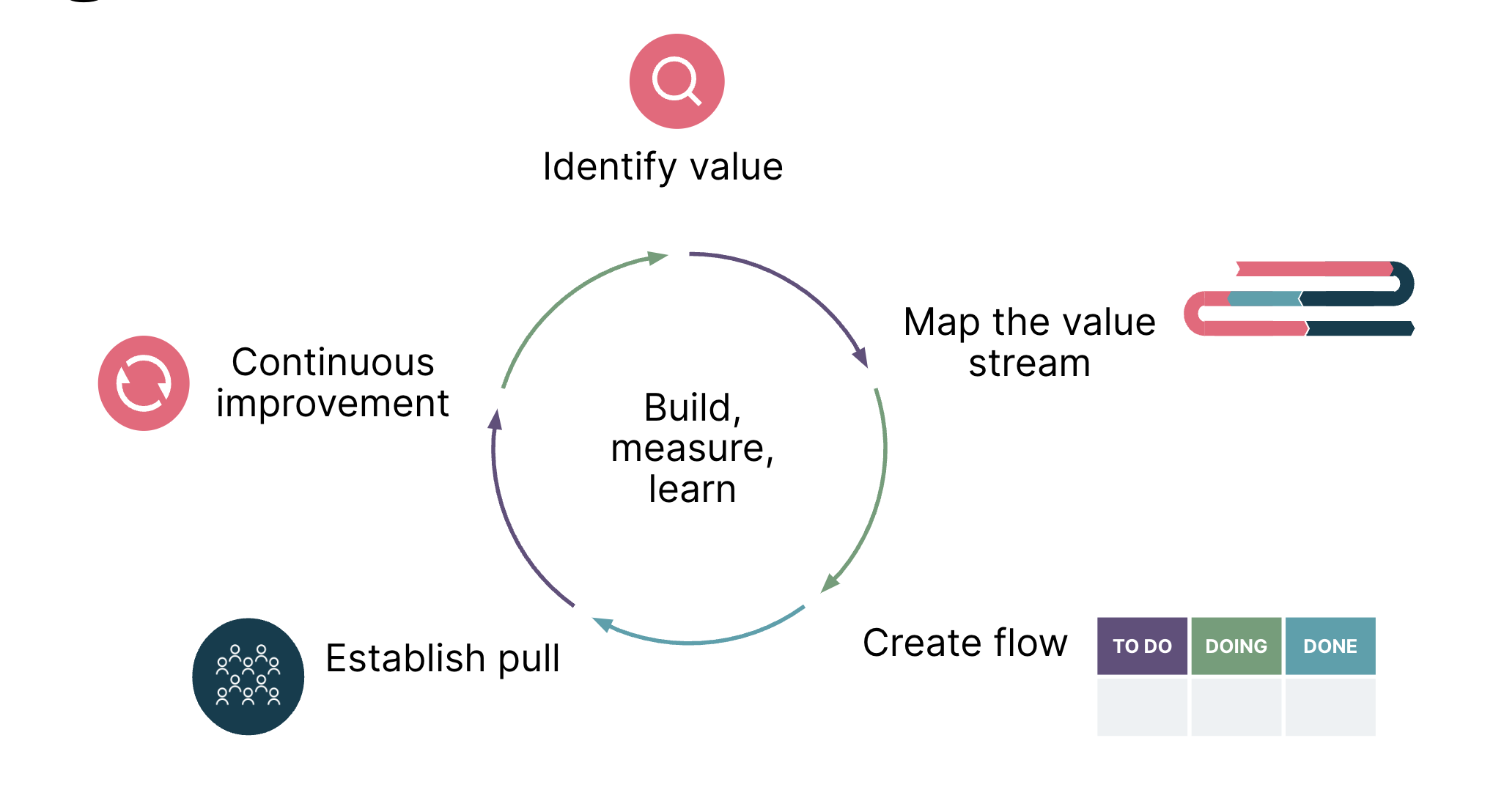
If you’re interested in how this looks for your organization’s ML journey, do get in touch with us.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

