














Technology strategy
Guiding the unknown: A compass on how to navigate complex strategic initiatives

Why does it still take hours — or even days — for organizations to truly understand what went wrong after an incident?
I’m currently deep in the aviation sector with my latest project, so I’ve been recently analyzing high-profile meltdowns in the industry. They’re invariably masterclasses in what happens when technology outpaces our ability to see into it:
British Airways, 2017: an uncontrolled power return turned a localized data center error into a global collapse. It stranded 75,000 passengers because, despite the alerts, the team lacked real-time visibility into the actual state of their backup systems.
Southwest Airlines, 2023: although a weather event triggered the initial delay, the week-long operational collapse happened because leadership lacked real-time visibility into where their pilots and crew actually were. Their legacy systems couldn't "see" the reality on the ground.
In both cases, and in many of the digital transformations I’ve been part of, there’s the same paradox: organizations can be drowning in dashboards but starving for clarity. When something breaks, the root cause remains invisible despite the constant pinging of alerts.
This is where observability comes in. Yes, it’s a technical discipline, but it’s also a leadership imperative. It gives you the confidence to not just know when things fail, but to understand why. In turn, that allows you to act faster and smarter.
In this piece, I’ll share a framework for thinking beyond monitoring:
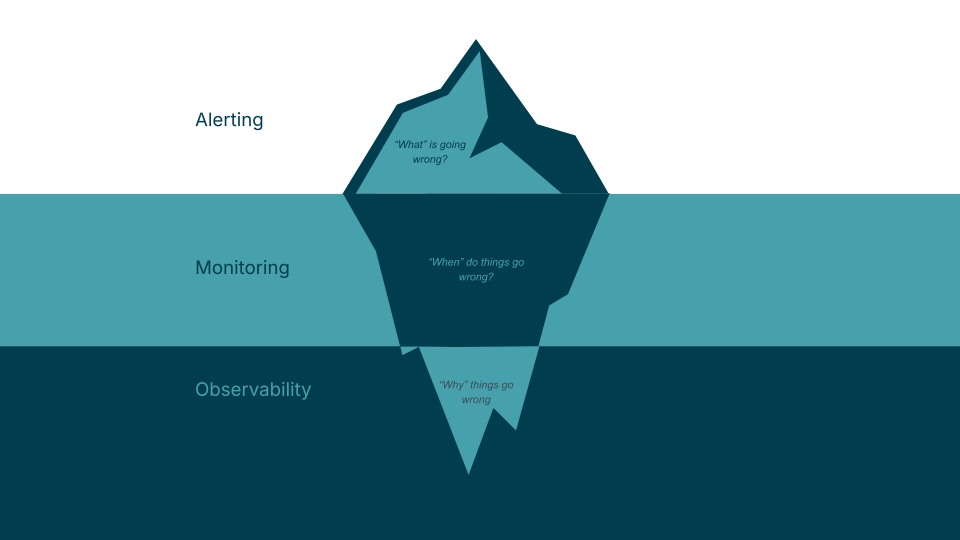
The difference between alerting, monitoring and observability.
Why observability matters as a core business strategy.
Strategic choices every leader needs to make.
Integrating insights into your governance and decision-making.
Alerting answers: “What’s going wrong?” It’s the most basic level — a notification that a threshold has been crossed.
Monitoring answers: “When do things go wrong?” It continuously collects logs and metrics, offering visibility into infrastructure for proactive maintenance.
Observability answers: “Why did this happen?” Observability is a cultural shift. It’s the ability to explain the internal state of a system based on the data it produces. It’s the difference between seeing a "Check Engine" light (alerting) and having a diagnostic tool that tells you exactly which sensor is failing and how it’s affecting your fuel mileage (observability).
For business leaders, observability is a direct line to your bottom line.
When a system fails, trust is undeniably bruised. However, that damage is compounded by the silence or lack of clarity that sometimes follows a "black box" incident. Observability allows you to replace "we’re looking into it" with a clear and informed explanation of the issue, as well as a concrete path to resolution. By providing this level of transparency, you move from a reactive "passenger" state to an active, professional recovery. It shows your customers that while failures can happen, you have the maturity and the tools to handle them with precision.
High observability reduces toil and empowers teams to solve problems without bottlenecks. But it goes deeper than just fixing things faster: it gives teams a profound understanding of how their systems actually behave under pressure. This clarity allows them to move from being reactive to being proactive, identifying weaknesses and reinforcing resilience before the next glitch even occurs.
Strategic ROI: knowing the why ensures your digital investments translate into reliable outcomes. If you don't know why a platform is slow, you might spend millions upgrading hardware when the issue was actually a single line of inefficient code.
Implementing observability isn’t about chasing the latest toolset; it’s about making deliberate choices that align with your business priorities. In my experience, there are four critical decisions leaders must make to move beyond simple monitoring.
1. Define meaningful signals
One of the first choices leaders — specifically product owners and business heads — face is how to handle the inevitable flood of alerts. When a system scales, alerts quickly devolve into noise with thousands of notifications that nobody acts on.
As a leader, your role is to define what actually constitutes a business-critical event. This requires a shift from technical alerts (e.g., 'CPU is at 90%') to managed alerts that focus on customer experience (e.g., 'the check-in process is taking 30 seconds longer than usual'). Many organizations are now beginning to augment this with AI-driven capabilities to reduce alert fatigue and accelerate root cause analysis. (We’ve explored this elsewhere in Bridging the SRE Gap: Towards autonomous observability and RCA.)
2. Solve the data patchwork
I’ve often observed organizations operating a patchwork of tools, each producing its own version of the three pillars of data:
Metrics: the numbers that, like a heartbeat monitor, tell you if the system is alive.
Logs: a timestamped record of every event, telling you what happened.
Traces: the journey, which tracks a single request as it moves through different systems, telling you where the bottleneck is.
The result of using different tools for each of these is fragmentation and duplicated effort. To fix this, leaders must move toward standardization.
Instead of just buying a tool, this means a strategic mandate to use OpenTelemetry. For a leader, embracing OpenTelemetry requires your teams to use it to instrument their code. This ensures your data is portable and consistent, regardless of which vendor's dashboard you use. It protects the business from vendor lock-in and ensures that if you change tools tomorrow, you don't lose visibility into your systems.
3. Balance oversight and autonomy
It’s tempting to mandate a single, centralized monitoring platform for the sake of efficiency. However, in my experience, a "one-size-fits-all" approach often holds back innovation.
A hybrid approach works better:
Central functions provide the governance, shared standards (like the OpenTelemetry mandate) and a "single pane of glass" for high-level health.
Individual teams retain the freedom to adopt specialized tools that fit their specific technical context.
This creates a culture of "freedom within a framework," achieving both coherence for the business and flexibility for the engineers.
4. The build vs. buy dilemma
Finally, we must confront the reality of where your engineers spend their time. Running a bespoke, in-house monitoring solution may feel like it offers more control, but it rarely provides a competitive edge in your market.
Building your own observability platform is like an airline trying to build its own fleet of buses to get staff to the airport; it’s a distraction from the core mission. Off-the-shelf solutions deliver robust capabilities at a lower total cost of ownership, leaving your teams to focus on high-value activities like refining business KPIs or building new features for your customers.
Observability shouldn't just live in the IT department. It should, in fact, inform your investment roadmap and product strategy. When you see repeating patterns in your why, it’s a signal to stop talking about maintenance and start talking about strategy.
For example, if observability data shows a specific business domain, like for instance, booking engine or payments, is hitting constant performance bottlenecks, that isn't just a bug for an engineer to fix. It’s a signal that the current architecture is a bottleneck for growth.
What I’m really advocating for here is a shift in how we prioritize work: using observability to move the re-platforming or modernization discussion from a gut feeling to a business necessity. It allows us to ask the hard questions during quarterly planning: Is our current tech landscape actually supporting our growth, or has it become a recurring liability that is slowing down our time-to-market?
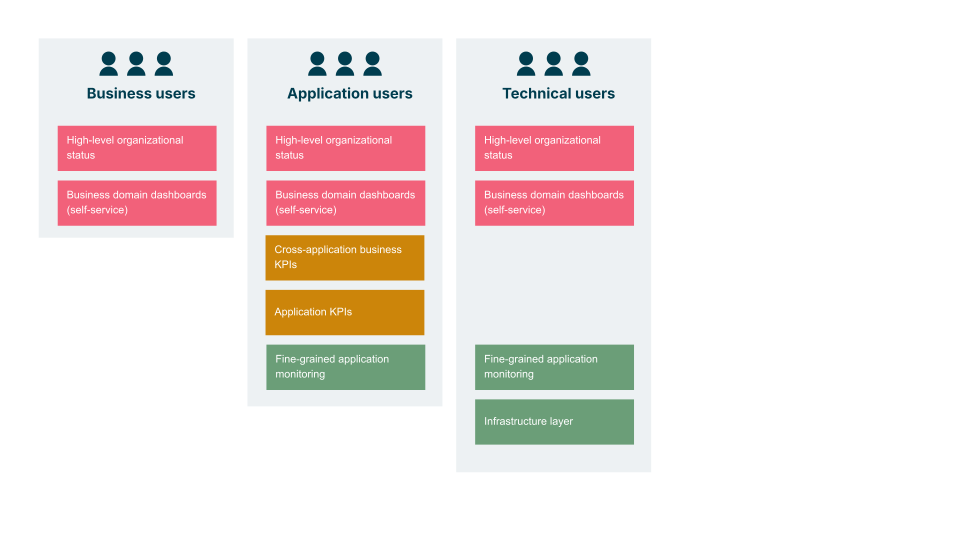
To ensure observability serves the whole business, I suggest looking at it through these layers of visibility:
High-level organizational status: A "business continuity" view for the C-suite.
Business domain dashboards: Tailored insights showing the health of specific lines of business (e.g., Cargo vs. Passenger).
Cross-application business KPIs: How systems collectively support customer outcomes, such as ‘time from search to booking.’
Technical layers: The under the hood data, which includes application KPIs, fine-grained monitoring and infrastructure.
Observability isn’t just about knowing when things break. It’s about understanding the why? So you can reduce impact, build trust and enable innovation.
As you look at your own digital platforms, ask yourself:
Do we have clarity when things go wrong, or just more noise?
Are we using what we learn to evolve our architecture, or are we just patching leaks?
At Thoughtworks, we’ve seen that organizations treating observability as a strategy — not just a toolset — gain a lasting advantage. They recover faster, innovate with more confidence and, most importantly, deliver the kinds of experiences their customers expect.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

