














Generative AI
AI isn't just a coding partner — it can be a deployment partner, too

As software-defined vehicles have risen in prominence across the automotive market, the industry is having to rethink its approach to architecture. We’re starting to see a shift from electrical design, involving many distributed electronic control units (ECU), to what’s called a zonal architecture.
To be sure, this change has many benefits: improved data flow, greater efficiency in software updates and over-the-air (OTA) functionality, to name just a few. However, it also requires significant codebase modernization. This is particularly challenging because a significant amount of code on which vehicle software runs is C++ — a language notorious for being hard to read.
That’s not the only challenge, though. Modernizing C++ in this context doesn’t just involve refactoring and optimizing existing code; it also needs to be integrated with new software layers to ensure compatibility with modern hardware and asynchronous communication protocols, such as CAN or SOME/IP.
Getting this right is crucial for the automotive industry. In this blog post I’ll explore how generative AI tools may be able to help us modernize tricky C++ code quickly. Such tools might just be critical if automotive manufacturers are to fully realize the potential of the SDV fast and remain competitive in a rapidly evolving landscape.
At Thoughtworks, we’ve developed a generative AI tool specifically designed to help teams modernize legacy code: CodeConcise. CodeConcise was initially developed to accelerate the reverse engineering of large COBOL codebases. However, it’s extensible and can be adapted to many other programming languages — including C++. We wanted to explore how we might use CodeConcise in an automotive and SDV context in the hope it would simplify and accelerate the modernization process. We started our experimentation onAutoware Universe, an open source software stack for self-driving vehicles developed by the Autoware Foundation, built on the Robot Operating System 2 (ROS 2).
Before we go further, it’s worth diving into how CodeConsise actually works. It consists of two parts: the analysis of the code it’s given and the UI which includes, among other things, a chat interface. So, before we can interact with the codebase using a chatbot or look at the capabilities that have been extracted by the LLMwe need to make it aware of our specific codebase.
CodeConcise makes use of RAG backed by a knowledge graph which is injected into a Neo4j database. This ingestion is the first phase:the code is inserted into the knowledge graph in a reasonable manner so in a later phase the LLM will later be able to understand the various parts of the codebase and how they fit together.
We saw that other language integrations made use of static code parsing to extract and ingest chunks. We started breaking down the code into classes, later in methods, then extracting namespaces. Eventually, we moved away from static parsing to CLANG (using LLVM libclang python bindings), a compiler frontend. This helped address the complexity of C++ and allowed us to implement various relationships between logical code chunks.
Once we did this we weren’t limited to only parsing the code; we also could make use of the syntax tree and insert parts of it into our graph.
The image below shows what the graph could look like after the ingestion:
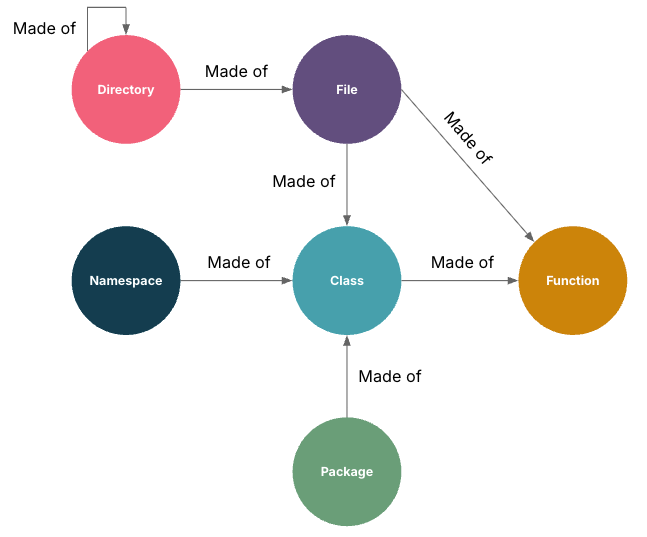
Breaking down our C++ codebase into chunks in the graph database is then used in the second phase in the analysis — which we describe as comprehension or understanding.
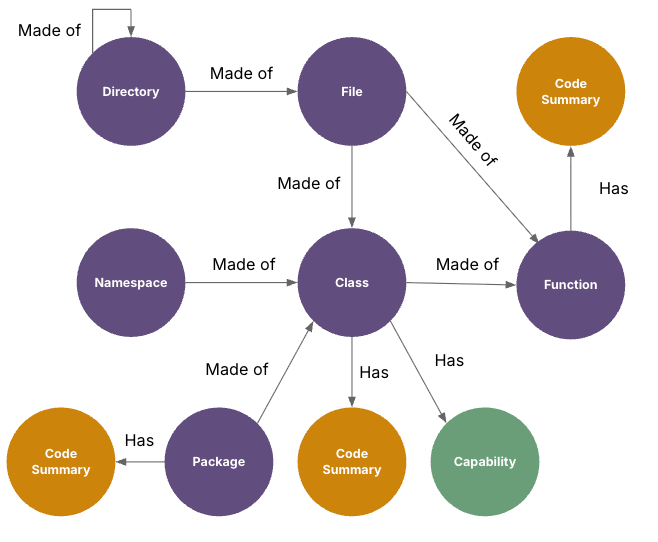
Here the tool is traversing the chunks and uses an LLM to summarize each chunk and then insert an embedding into the database. Business capabilities for our codebase were also extracted at this stage.
So, in the ingestion phase we try to create an understandable context for the LLM; in the comprehension phase we use AI to add customizable details to the knowledge graph. After finishing ingestion and running comprehension on our basic code chunks and the relationships between them we were finally able to make use of the chat interface to dive deeper into the codebase and ask questions about it.
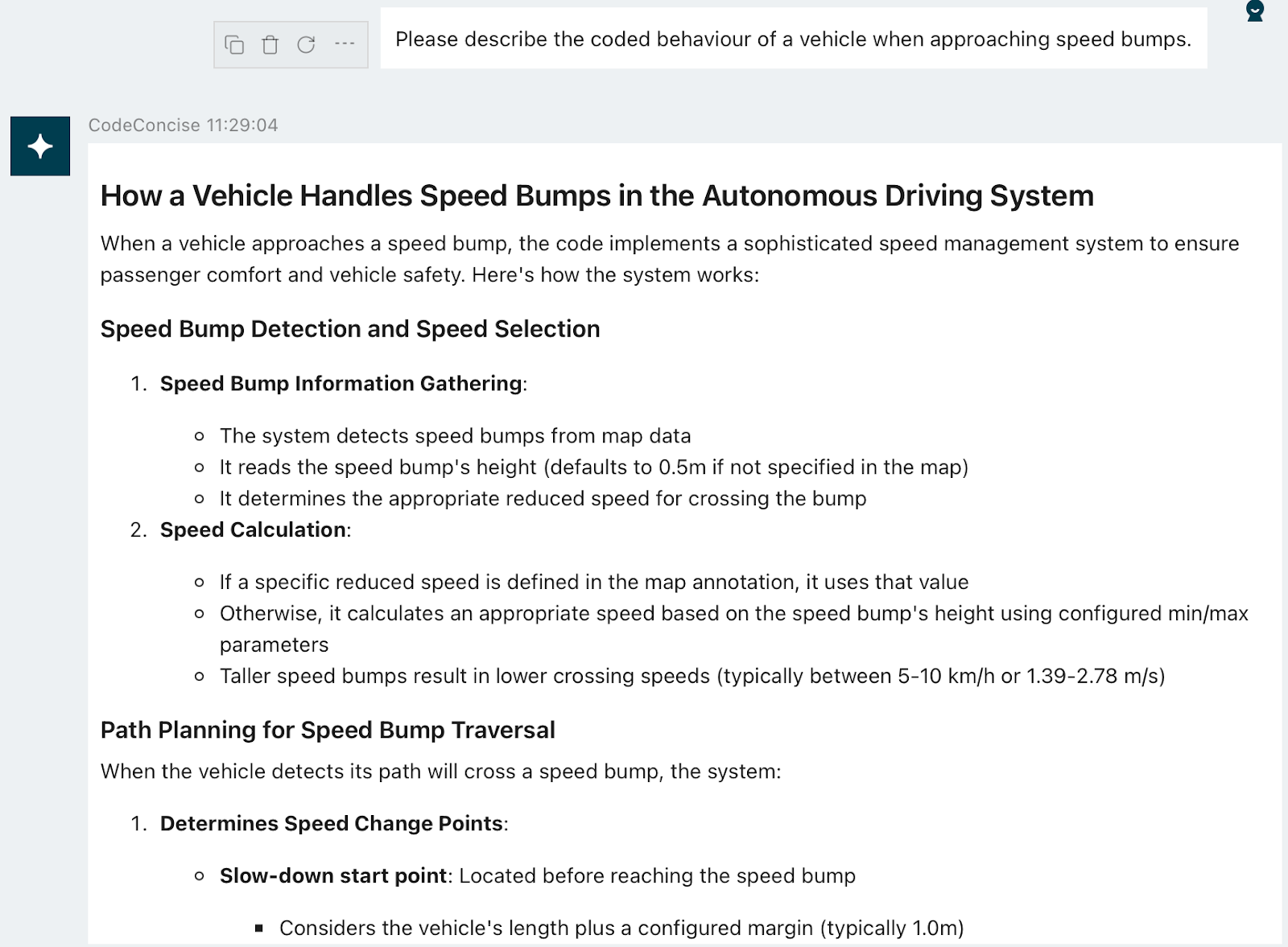
This was already pretty great: by ingesting code chunks, we could leverage existing features so the LLM could understand our codebase. The chatbot's ability to explain code and business capabilities meant we were able to grasp the fundamentals of how the codebase worked without extensive manual reading and analysis.
Building on this success, we then explored how quickly additional features could be added. We believe many legacy codebases lack a rich architectural picture; that means we need to extract not only business knowledge but also create an explanation of how the code works together.
Realizing most legacy C++ projects use CMake, we experimented by extracting specific types of code chunks in the initial ingestion phase called packages, which were based on information in the CMake file. We then implemented an agentic component view (Level three) based on the C4 model that applies the traversal mechanism on the extracted packages and their summaries.
This view utilizes CMake compilation targets, which groups related source files, as input. We created an architectural element between the C4 model's component view (level three) and the code view (level four) to bridge the gap between our build system and the C4 model's hierarchy. The agentic file parser, already present in CodeConcise, was used to parse ROS2 launch files and to identify the relationships between packages. The components can afterwards inherit the relationships between the underlying packages because components and packages always have a 1:n relationship. The approach of the agentic parsing has been chosen to make an extension to other asynchronous communication protocols such as SOME/IP easy and to demonstrate how to quickly extract information in an otherwise heterogeneous setup where traditional parsing reaches limits quickly.
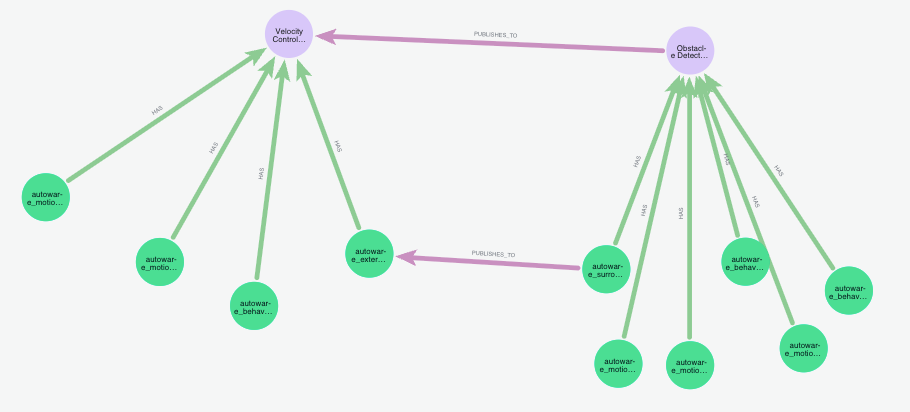
The image above shows how many packages contribute to a component, while maintaining extracted relationships.
We've observed how AI can significantly accelerate our ability to understand unfamiliar codebases. CodeConcise itself offers considerable flexibility, easily adapting to various needs despite some initial technical hurdles.
This experience also demonstrates the true potential of AI, highlighting how, if we also leverage robust engineering practices, it can yield substantial benefits.
However, we did still encounter challenges. For example, we had to implement workarounds for the LLM’s context limits and address hallucinations by writing better prompts for the model. Furthermore, the underlying technical foundation is rapidly evolving; this means it remains somewhat immature. Nevertheless, we successfully showcased how AI can be leveraged to assist in solving complex problems.
Many thanks go to my team – Christoph Burgmer, David Latorre, Zara Gebru – not only for the work on the project but also for giving me great feedback.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

