














AI and ML
How MCP can help us investigate security incidents faster

Model Context Protocol (MCP) is an emerging standard for integrating semantic context into AI agents, a key enabler of an end-to-end site reliability engineering (SRE) practice.
In an environment where autonomous agents increasingly handle operational tasks, MCP empowers these agents with fact-based, consistent, rich contextual information necessary for effective knowledge retrieval, decision-making and autonomous collaboration.
This article explores MCP through a strategic lens, highlighting its transformative role in SRE, and demonstrates its practical value using a real-world MCP server example focused on incident investigation related to external events.
Model Context Protocol (MCP) is an open standard developed by Anthropic, facilitating semantic context sharing among AI agents. In complex operational environments, AI agents often struggle with limited task-specific context, leading to ambiguous actions, misinterpretations, hallucinated outputs and wrong decisions.
MCP addresses these challenges by embedding a standardized semantic layer into agent interactions, ensuring that each agent operates with the relevant context it needs. By systematically managing and sharing semantic context, MCP significantly improves the consistency, accuracy, and efficiency of agentic workflows, ultimately lowering the operational cost and enhancing AI performance and decision-making across the system.
In modern SRE practices, context is the cornerstone of effective incident management — from triaging and acknowledgment to troubleshooting, resolution and post-incident analysis. SRE is inherently a high-cognitive-load task for IT operations professionals, where context is always shifting, and acquiring and updating operational knowledge is paramount.
As observability and operations tooling providers increasingly introduce AI agents into their ecosystems, they realize that common approaches — using generic large language model (LLM) knowledge or retrieval-augmented generation (RAG) — cannot solve the context problem where AI agents are adopted for specific enterprise environment. This is where MCP becomes particularly valuable.
Below diagram describes a typical SRE agentic workflows enabled by MCP:
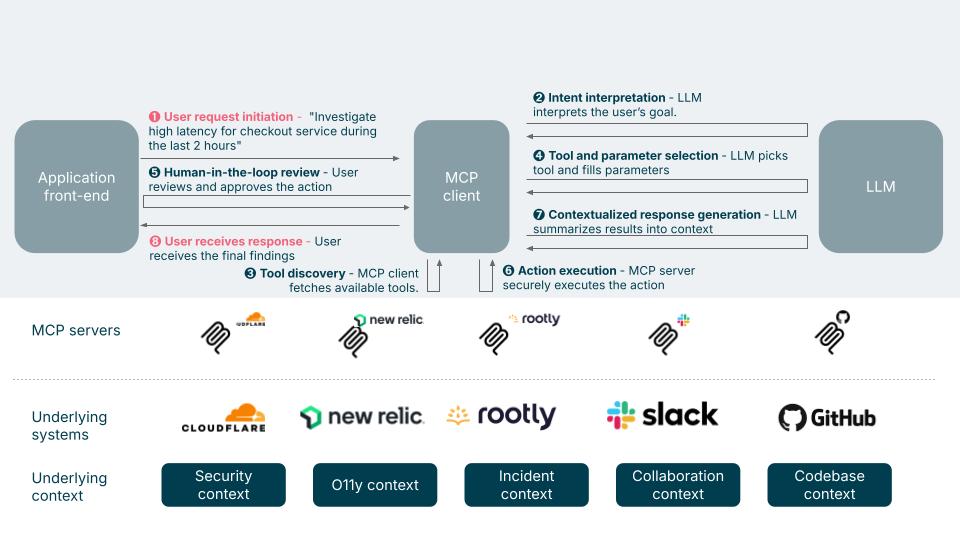
Step 1: Application frontend (e.g., incident investigation UI) captures a user request
A user (e.g., an SRE engineer) requests (1): "Investigate high latency for checkout service during the last 2 hours."
Step 2: MCP client interprets the user intention
The MCP client will use an LLM to determine which MCP Server to call based on the investigation type (e.g., traffic analysis, anomaly detection, logs inspection) by interpreting the user goal.
Step 3: MCP client fetches tools from the SRE MCP server(s)
The MCP Server advertises available "tools" such as:
Query service logs (e.g., via cloud logging, Datadog logs)
Retrieve metrics anomalies (e.g., via Prometheus, Chronosphere)
Post status updates to incident Slack channels
Search previous similar incidents or RCA reports (e.g., via an internal knowledge base)
Step 4: LLM determines specific tool and parameters
The LLM selects the appropriate tool and parameters:
➔ "Query latency metrics for checkout-service pod in prod-cluster-1 from 10am–12pm."
Step 5: Human-in-the-loop approval
The user reviews and approves the LLM-suggested action plan.
Step 6: MCP server executes the action securely
The MCP Server wraps secure access to the appropriate system:
➔ Fetch latency metrics via Prometheus API, summarize results, and post findings back to the investigation UI or Slack channel.
Step 7: Response augmentation by LLM
The LLM augments raw execution results with context-aware insights and presents them in a user-friendly format.
By applying this flow, MCP clients and servers allow AI agents to consume internal and external knowledge, precisely identify and resolve incidents, proactively detect anomalies, and collaborate across different systems without losing critical context. This persistent context awareness enhances both the accuracy and speed of reliability operations, making SRE an ideal domain for MCP adoption.
Like any emerging technology trend, executive leaders must make a strategic decision regarding MCP adoption. MCP acts as a context-as-a-service provider — meaning its value depends heavily on the AI agents consuming it. Organizations should consider investing in MCP if AI agents already play a significant role in their reliability engineering and IT operations workflows.
If your organization leverages cloud-native or SRE tool providers’ AI agents — such as Amazon Q, Google Cloud Assist, Dynatrace Davis, or Datadog Bits AI — embedding MCP can substantially enhance their effectiveness.
Furthermore, if your operations frequently suffer from context loss, misinterpretations or inefficiencies in AI-driven interactions, or if you are building homegrown AI agents that require persistent, structured domain knowledge, MCP becomes critical to sustaining autonomous operations.
From a producer perspective, MCP investment is particularly strategic if your observability toolchain providers, such as Rootly or GitHub, are offering MCP server solutions.
However, MCP investment should be reconsidered if your organization's operational knowledge is not yet fully semantically mapped, your AI-driven system complexity remains low, or your current tool providers do not yet support MCP. Additionally, if immediate budgetary constraints outweigh longer-term strategic advantages, delaying MCP adoption may be a prudent choice.
Let’s use a practical use case to illustrate how an MCP-integrated AI system really works
In SRE, incident response relies heavily on internal signals including metrics, logs and traces, but what if the “incident” isn’t technical at all?
We encountered a case where platform traffic dropped during what appeared to be peak usage hours. After extensive troubleshooting, the team discovered the dip coincided with a widely watched international sporting event. Again, no system issue — just a missing piece of external context.
The example highlights a classic gap in traditional incident management where internal telemetry alone does not explain user behavior. Without dynamic context — events, regional usage patterns, weather, or holidays — SRE teams risk misinterpreting signals, wasting effort or even escalating non-issues.
Incident management platforms increasingly see themselves as key context providers, connecting diverse semantic signals to AI systems. One such implementation is Rootly’s MCP server, which is:
Leveraging large language models (LLMs) via MCP to interpret semantic context behind traffic anomalies.
Integrating external sources (e.g., Holiday API, Calendrific) to enrich the context available to AI agents.
Supporting AI agents to classify anomalies, helping distinguish genuine incidents from expected behavioral patterns.
One interesting use case is Rootly AI Labs’s EventOrOutage, it is an MCP server function to allow an incident triager AI to reference an external context or multiple to deciding if the drop in traffic incident is genuine or caused by an external event such as a national holiday, sport event. This is how it works:
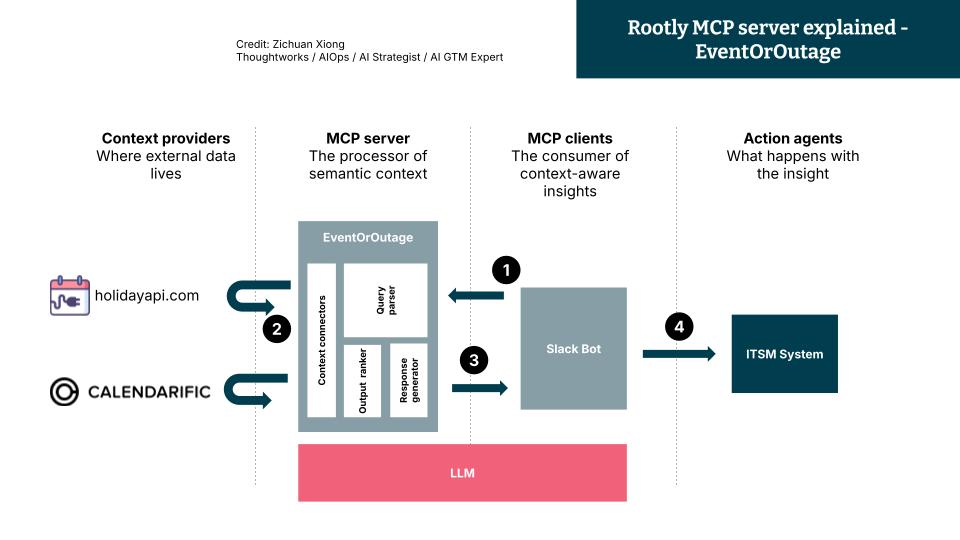
Step 1: User request initiation via Slack Bot - A user triggers a request through a Slack bot: “Validate this incident.”
Step 2: Semantic context retrieval via MCP server - The LLM embedded in the MCP Server parses the request using a query parser, then calls external context providers (e.g., HolidayAPI, Calendarific) to retrieve relevant contextual signals.
Step 3: Response augmentation - The LLM enriches the response from the MCP Server with the retrieved context and formats it into a human-readable summary.
Step 4: Workflow curation by MCP client (Slack Bot) - The Slack bot, supported by the MCP Client, uses the LLM-generated summary to trigger downstream actions — e.g., automatically posting a comment to the relevant incident in the ITSM system: “This might be a related event — please investigate further. See details below.”
This flow represents a context-aware incident handling process with MCP servers integrated with a few agentic AI systems and large language models.
Early experiments with the MCP have demonstrated substantial benefits, including:
Reduction in alert fatigue through accurate identification of genuine incidents from routine events.
Enhanced operational efficiency and quicker response to real issues.
Improved productivity through context-aware AI automation.
Adopting MCP, particularly with practical implementations, significantly enhances semantic contextual capabilities within AI-driven reliability engineering and incident management. Organizations leveraging MCP can expect improved operational effectiveness, greater precision in incident management as well as other use cases, and strategic resilience in AI-driven operational landscapes.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

