














The situation: As a multi-tenant cloud service, Mingle uses ElasticSearch as its search facility for card, page, and murmur content, indexing all content to a single ElasticSearch node. However, a series of problems (hitting hard file descriptor limits, OOM errors, and corrupted indexes) forced our team to reassess the infrastructure.
The solution: We started building a new ElasticSearch cluster with AWS OpsWorks based on an AWS blog post titled “Deploying ElasticSearch with OpsWorks.” As we adapted the AWS template to our needs, it became apparent we needed to create our own repository with the increasing changes, including newer Chef cookbook versions, additional configuration options, support for other infrastructure miscellany such as Papertrail , and an Elastic Load Balancer, and a Rake task to make deployment dead simple. Better yet, we’ve open sourced our solution for the community to use.
Some Background
Mingle had given each client site its own ElasticSearch index to keep data/search results separate to a given site. This worked well in the beginning, until we hit our first limitation: we exceeded the file descriptor limit. This was quickly solved delayed by increasing the soft limit to a large number. As we tracked our growth, we realized that this design simply would not scale: we would eventually hit the hard OS limit. It was time to rethink our multi-tenancy solution for our ElasticSearch integration.
We migrated all our indexes to a single, unified index, separating customer data with unique tokens. This fundamental change gave us a much more reasonable open file descriptor growth rate, allowing us to scale over the two years since its inception.
ElasticSearch on AWS
The initial incarnation of our ElasticSearch instance ran on single EC2 node. Because we had a sizable index, we wanted to preserve our data in the event of an EC2 failure and chose to store our index on S3 using the now-deprecated S3 gateway. Per ElasticSearch recommendation, we used an EBS volume as a local cache for performance. As we were on an ancient version of ElasticSearch (0.19.1) and the ElasticSearch team had discontinued support for the S3 gateway plugin, our setup was far from an ideal solution.
Despite this, our setup largely worked for a long time. Every so often, we found issues with our index, but usually a brute-force reindex would solve it. If we had issues remounting our EBS volume after swapping out EC2 nodes, we could make a full recovery through the S3 gateway. On the upside, things appeared to be chugging along.
On the downside, running obsoleted versions in our infrastructure meant we could not take advantage of newer and useful features, such as index snapshotting and index aliasing. Moreover, only a select few team members were actually familiar with the convoluted deployment of our custom ElasticSearch node, which relied on a custom-built AMI, an internally built bootstrapping Debian package, and some of the oldest Ruby code in our deployment codebase. However, as long as our ElasticSearch setup continued to work, addressing infrastructure debt was always “something we could get to later” for our small development team.
When Things Go Bad
The sad fact is that more often than not, Bad Things are the driving force for actual improvement. Nothing motivates your team to fix a broken design faster than frequent failures in production. Here’s how Bad Things began to manifest for Mingle:
Massive increase in index size
A few months ago we added more customers with some very large projects. This substantially increased our indexable data set, and this growth was compounded when we enabled a feature to allow indexing of arbitrary and dynamic properties in support of more flexible searches. As our index and user requests continued to grow, we began to run into OOM errors. While increasing the heap size was a quick bandage, this was one of the early signs that our infrastructure would buckle as we grew.
Index corruption and slow recovery
Soon enough, we started seeing various failures, resulting in index corruption. Customers reported that search was broken more and more frequently. Early on, reindexing would bring the index back to a consistent state; now that our index size had grown, reindexing meant several hours of downtime for our search service. To reduce the turnaround time, we found a way manually remove corrupted data from our index, but it was still a painful process. When the failures began to happen on several times weekly, we knew the time had come to rethink our infrastructure.
Revamp of Our ElasticSearch Service
As an outcome of the continued maintenance of our ElasticSearch node, we took home a few lessons and did not want to repeat our mistakes. Our redesign goals were:
- Be scalable when data increases: we should not vulnerable to large amounts of data.
- Automatic sharding and replication to maintain availability and performance.
- Simple, resilient deployments so that anyone on the team can understand and improve it.
- Zero downtime.
- Don’t reinvent the wheel! Remove dependencies on homebuilt AMIs and packages.
In our search for an existing solution, we found one published by the AWS team itself. It included a simple deployment strategy, used lots of off-the-shelf software, and was open source. These were encouraging signs that we could quickly build our own cluster from others’ experiences.
Building the ElasticSearch Cluster
We started building a new ElasticSearch cluster with AWS OpsWorks based on an AWS blog post titled “Deploying ElasticSearch with OpsWorks.” It was fully automated with OpsWorks and CloudFormation, used maintained and open sourced Chef cookbooks, and was well documented. Being an open source backed design, a lot of the heavy lifting around the deployment and bootstrapping was already done, and we could leverage the public mindshare in the event of any issues. As the blog post was a bit old (cloud years are functionally equivalent to dog years), we updated to newer cookbook versions to support the latest versions of ElasticSearch. We generally followed the architecture recommended by the AWS team, adding and modifying cookbooks and components to work in Mingle’s infrastructure, and things been running smoother than ever.
For the first time, our team had an easy way to deploy a multi-node, multi-master ElasticSearch cluster with zero downtime. Moreover, we were finally on a modern version of ElasticSearch (1.3.5), allowing us to benefit from all the new goodies it brought, such as index snapshotting, and rolling upgrades. Quite surprisingly, we made only minimal changes to our integration with Mingle to support the move from 0.19 to 1.3—truly a tribute to the great design by the ElasticSearch team.
It’s Open Source
As we were adapting the CloudFormation template to meet the needs of our production environment, it became apparent we needed to create our own repository with the increasing changes, including newer Chef cookbook versions, additional configuration options, support for other infrastructure miscellany such as Papertrail, and an Elastic Load Balancer, and a Rake task to make deployment dead simple. And now, we’ve made it open source on GitHub.
Usage
While the full details on usage are available in the README.md on GitHub, you can find a quick summary below.
Prerequisites
- AWS credentials and an EC2 SSH keypair
- The default aws-opsworks-service-role and aws-opsworks-ec2-role roles created by OpsWorks
- SSL certificate uploaded to AWS (for the Elastic Load Balancer)
- Domain name for the cluster endpoint and a Route53 Zone
Deploying
The only hard requirements to get this working are Ruby, Bundler, and Rake. We’ve included a shell script to set everything up, including rbenv, but feel free to install Ruby any way you wish.
Once you have cloned the repository and have run bundle install, deploying a cluster is generally a matter of:
- Setting up minimal environment variables (e.g. your AWS credentials). If using rbenv or rvm, you can write these values out to .rbenv-vars or .ruby-env. See the rbenv-vars.example file for all environment variable configurations.
- Run: rake provision
This is will stand up a cluster (3 nodes by default) listening only on HTTPS with a basic authentication challenge.
Papertrail
Papertrail is our log archiver of choice, and if you would like to push the cluster’s logs to your
PAPERTRAIL_ENDPOINT=logs.papertrailapp.com:
Results
Upon a successful deployment, you should be able hit the elasticsearch-head cluster frontend at https:///_plugin/head:

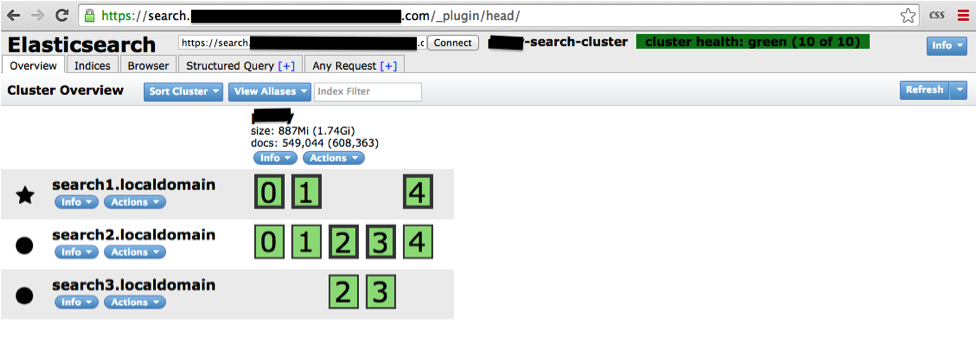
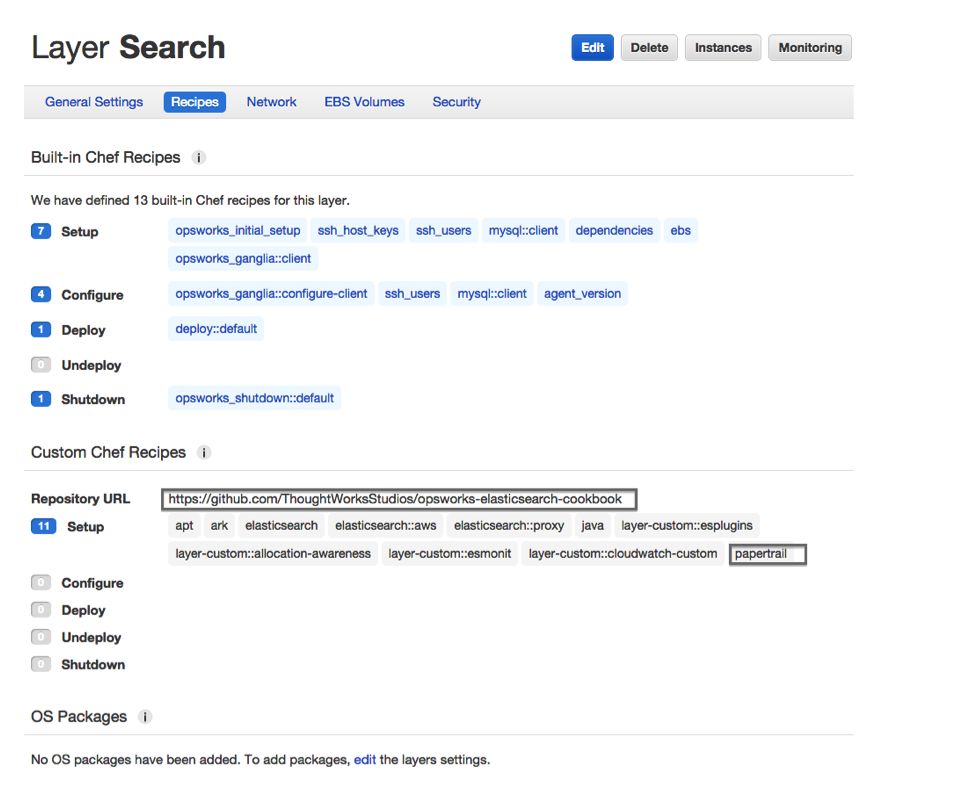
In your AWS OpsWorks console, under the Layer > Recipes section, you should see the following:

We are deriving a lot of value from this design and as a result are worried about availability and resilience. Even so, as with anything else in production, remember that it’s still important to monitor your cluster.
Comment or tweet us (@thatsmingle) if you happen to use our solution or modify it, and let us know what your results are.
Note: this article originally appeared on Mingle blog.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.