














Generative AI
The Model Context Protocol: Getting beneath the hype

Modern distributed systems demand proactive and precise incident investigation to minimize downtime and reduce operational burden. At Thoughtworks Managed Services, troubleshooting isn’t just a technical necessity — it’s a business-critical function. Effective root cause analysis (RCA) translates directly into cost savings and operational efficiency across downstream support activities.
To deepen our investigative capabilities, we’ve embraced technologies like eBPF, which offer visibility into kernel-level behavior. Groundcover, a leader in this space, makes these ground-level insights accessible in real time without requiring deep kernel expertise from every engineer.
At the same time, we’ve been embedding AI agents into our operational toolchain to augment and accelerate the work of our human engineers. With the rise of the Model Context Protocol (MCP), a new standard is emerging that allows AI agents to go beyond static Q&A and interact directly with live systems and data sources.
Accessing kernel-level data through Groundcover has now become a cornerstone in upgrading our AI agents for more intelligent and context-aware incident investigation. In this blog post, we share the background, our approach, the integrated solution we built with Groundcover and the results we’ve seen so far.
In our daily support operations, the incident investigation process often begins with correlating logs to understand the underlying issue. Once an SRE engineer receives an incident from the incident management platform, they typically conduct a multi-dimensional investigation (Diagram 2) that includes:
Metrics — Analyzing time-series data across dashboards to identify anomalies in performance or resource usage.
Logs — Searching distributed log sources for error patterns, exceptions or key terms related to the affected component.
Traces — Following request traces to pinpoint slow or failed spans and locate the origin of degraded user experience.
Events — Reviewing system and infrastructure events (e.g., restarts and deployments) that may correlate with the incident timeline.
Topology — Mapping dependencies between services to understand the potential blast radius and upstream/downstream impact.
Changes — Investigating recent configuration, code or infrastructure changes that could explain behavioral shifts.
The outcome of these investigative activities typically leads to one of three types of solutions:
A short-term fix to mitigate the immediate issue.
A recommendation for improving observability, such as adjusting alert thresholds or introducing new metrics.
A longer-term improvement suggestion targeting underlying architectural or systemic weaknesses.

Crafting these resolutions often requires drawing from diverse domains of knowledge, including system design, observability best practices and service-level objectives. While this traditional approach is structured and thorough, it remains time-consuming — especially when dealing with low-level system signals and fragmented toolchains.
To address these challenges, we began adopting AI agents to support our incident workflows. While using agents to retrieve knowledge from multiple sources proved somewhat helpful in suggesting solutions, we quickly realized a key limitation: effective investigation requires access to real-time, system-level data. Without up-to-date context from the source systems, the AI’s suggestions risk being either too generic or already obsolete by the time they’re generated.
This led us to a critical question:
How can we make investigational data collection more real-time and accurate — so AI Agents can generate more relevant and actionable insights and solutions?
That’s where MCP — and its federated search capabilities — comes in.
In incident investigation, O11y platforms like Groundcover provide a powerful foundation by combining eBPF-based kernel-level telemetry with contextual heuristics through relational retrieval. This gives investigators rich and real-time system context.
When paired with AI agents enabled by Groundcover’s MCP Server, this paradigm allows reasoning to go beyond static knowledge retrieval, enabling dynamic actions like observability queries, live system searches and automated remediation (Diagram 2).
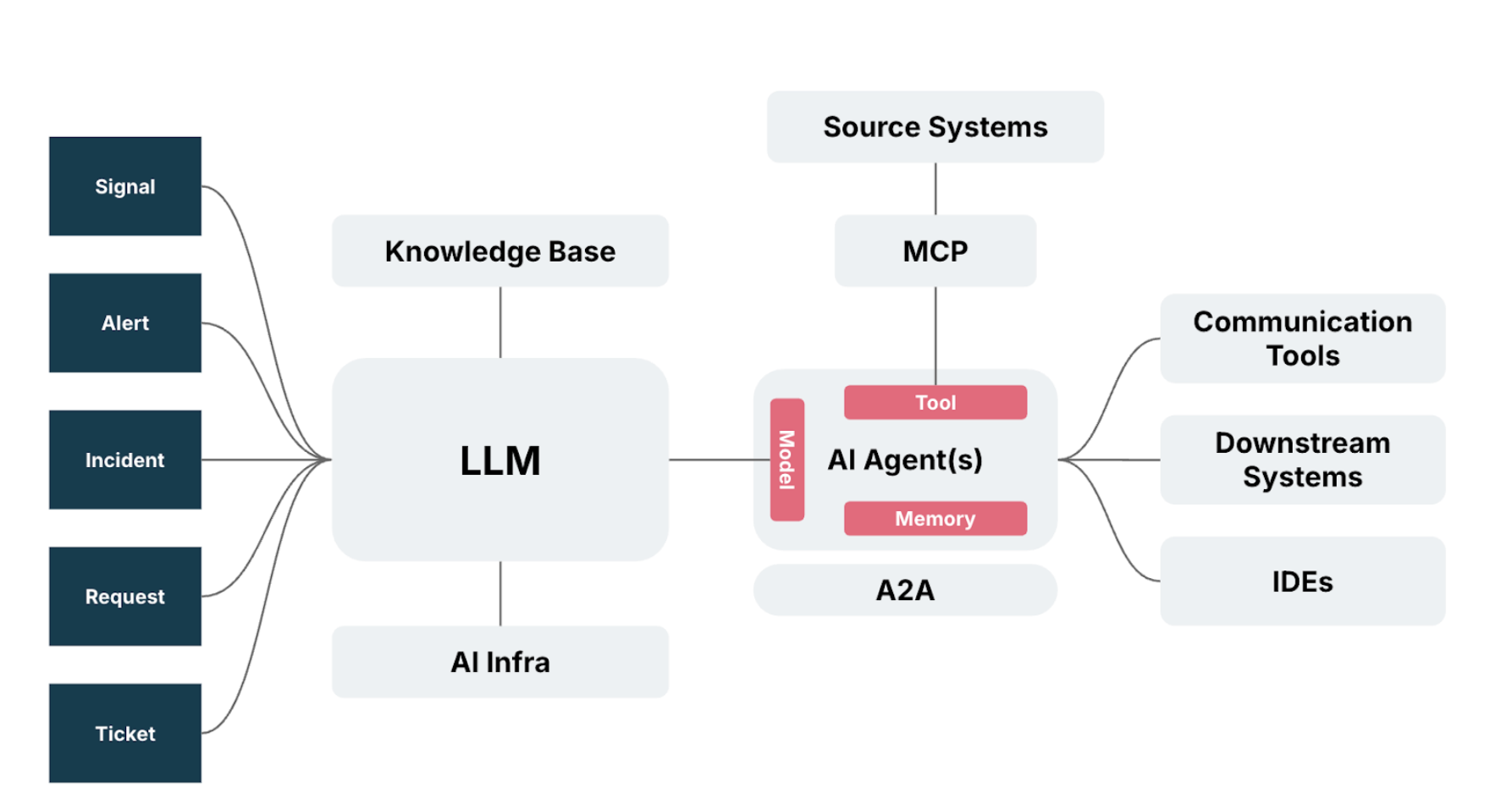
The result: faster, more precise and context-aware decision-making during incident investigation.
Our hypothesis, then, is:
MCP-enabled AI agents can significantly enhance speed and accuracy in deep system investigations.
Together with Groundcover, we built a solution to validate how AI agents can assist us in kernel-level incident investigation workflows. Our integrated solution demonstrates how AI agents use Groundcover and MCP to perform automated and contextual root cause analysis.
An AI agent collaborates with the Groundcover MCP server to perform real-time, context-rich root cause analysis (RCA) by dynamically retrieving observability data, constructing and refining triage plans and synthesizing insights into actionable resolutions.
Below is the workflow of an AI agent that leverages the Groundcover MCP server to conduct real-time, collaborative incident investigation. It retrieves observability signals, formulates triage strategies and iteratively drives toward root cause and resolution (Diagram 3).
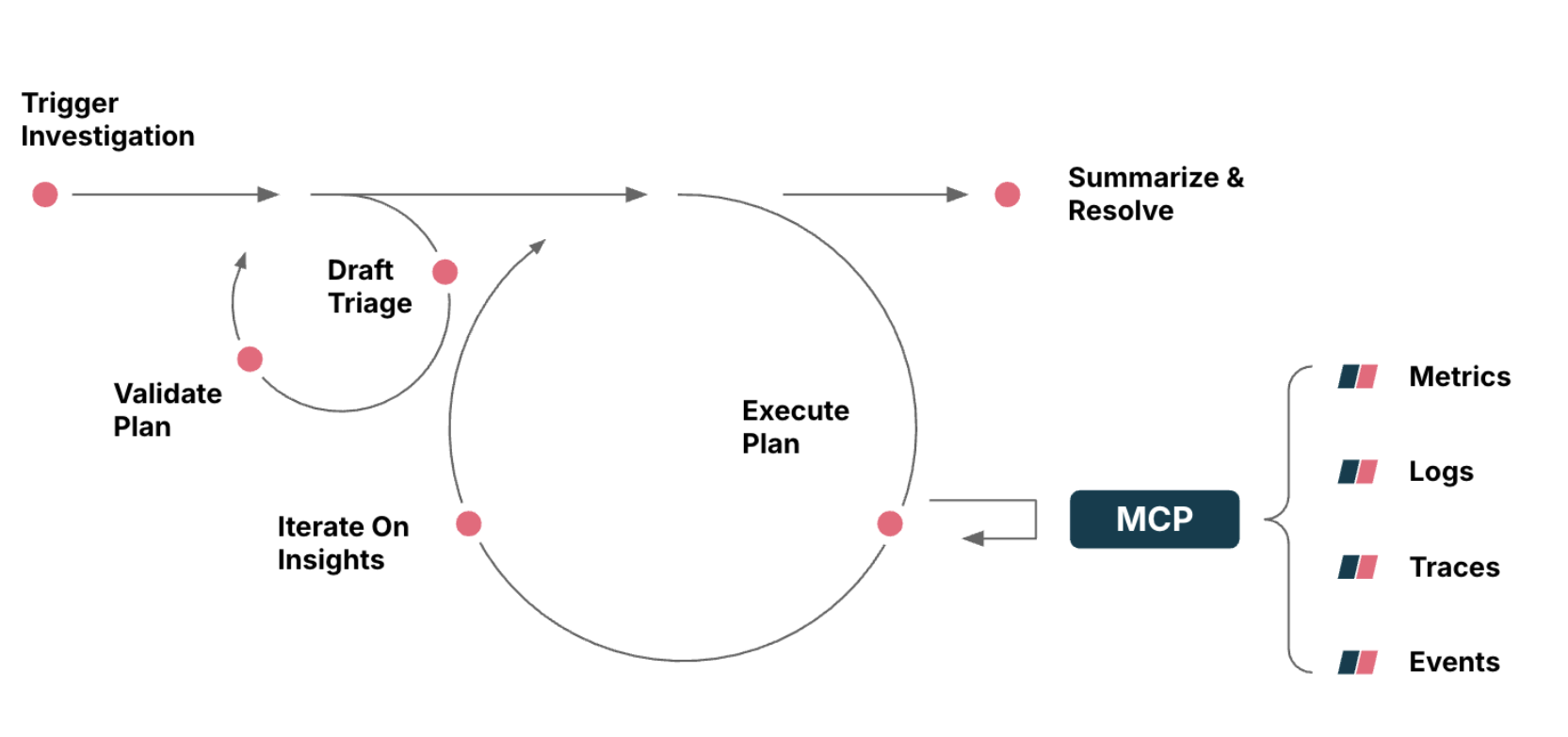
Step 1. Trigger investigation. A human agent initiates the investigation by prompting a natural-language question (e.g., “Why is checkout failing?”), which retrieves the most relevant active alert via the Groundcover MCP.
> Prompt example:

Step 2. Draft triage plan. An AI agent proposes a triage plan by exploring multiple investigation paths — each backed by specific data it needs (e.g., logs for error correlation, metrics for latency trends, traces for dependency failures).
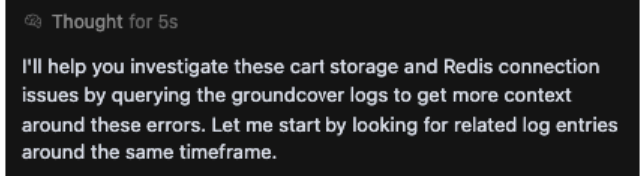
Step 3. Interactive plan validation. The human agent validates the AI's approach through iterative dialogue. In this experiment, it was discovered that overly generic prompts could lead to model hallucination. For instance, a vague prompt like "using groundcover mcp can you diagnose what is happening with the cart workload" caused the AI to incorrectly search for local files.
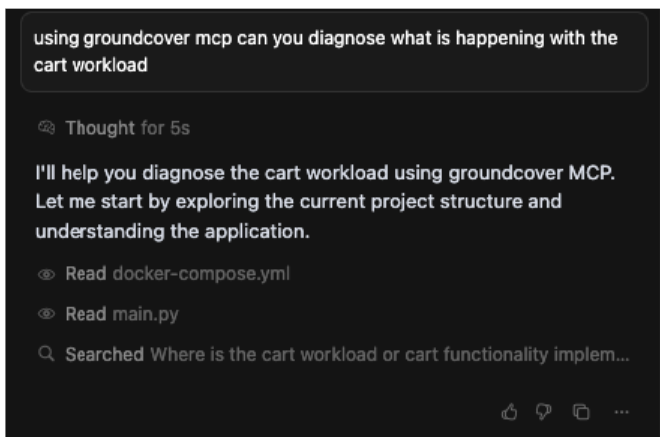
The human agent refined the plan by providing a more specific prompt, guiding the AI to compare different timeframes and focus on specific services. This course correction is a critical part of the collaborative workflow.
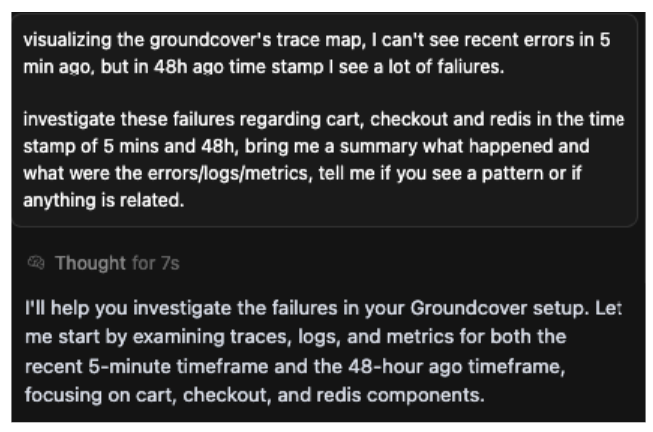
Step 4. Real-time execution. Following the validated plan, the AI agent executes the investigation by making real-time calls to fetch live telemetry. The Groundcover MCP server acts as a unified API gateway, allowing the AI to retrieve all the necessary observability signals (metrics, traces, logs) from a single source without needing to manage multiple endpoints. The AI's internal logs showing "Ran tool" multiple times are evidence of this real-time data retrieval.
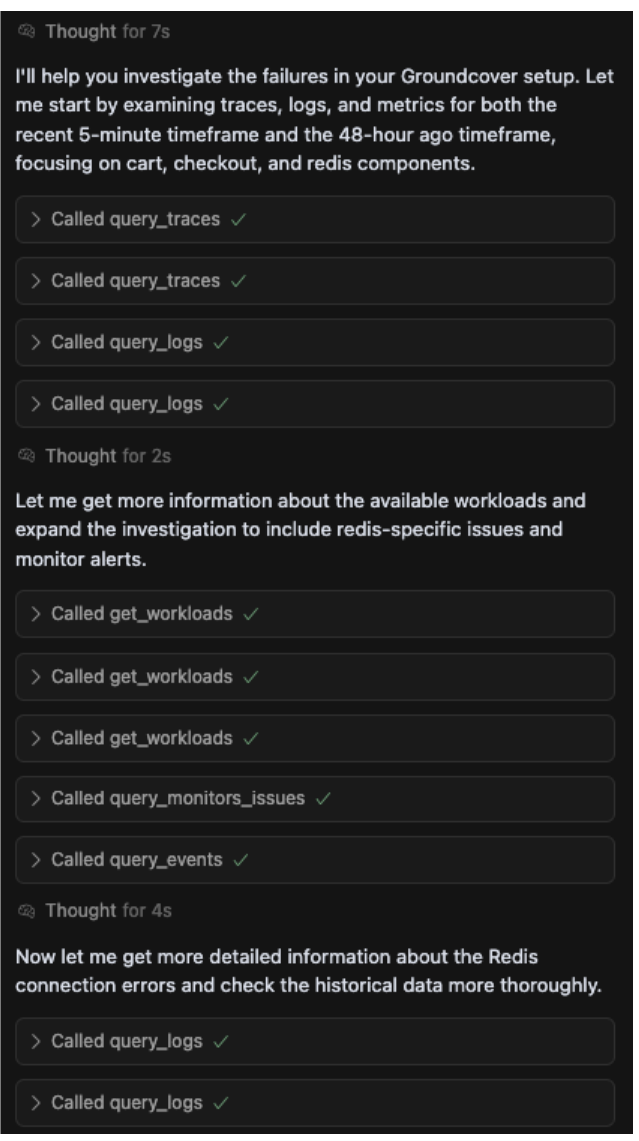
Step 5. Iterate on insights. Based on initial findings, the agent dynamically adjusts the triage path — looping back as needed, incorporating new hypotheses and data to refine the diagnosis. The process is transparent and iterative, as shown in the agent's thought process log.
The agent forms a hypothesis (e.g., "let me get more details about Redis connection errors"), executes a series of queries against different data sources (query_logs, query_traces, query_metrics) and then uses those findings to form a new, more refined hypothesis (e.g., "now let me check the memory usage patterns").
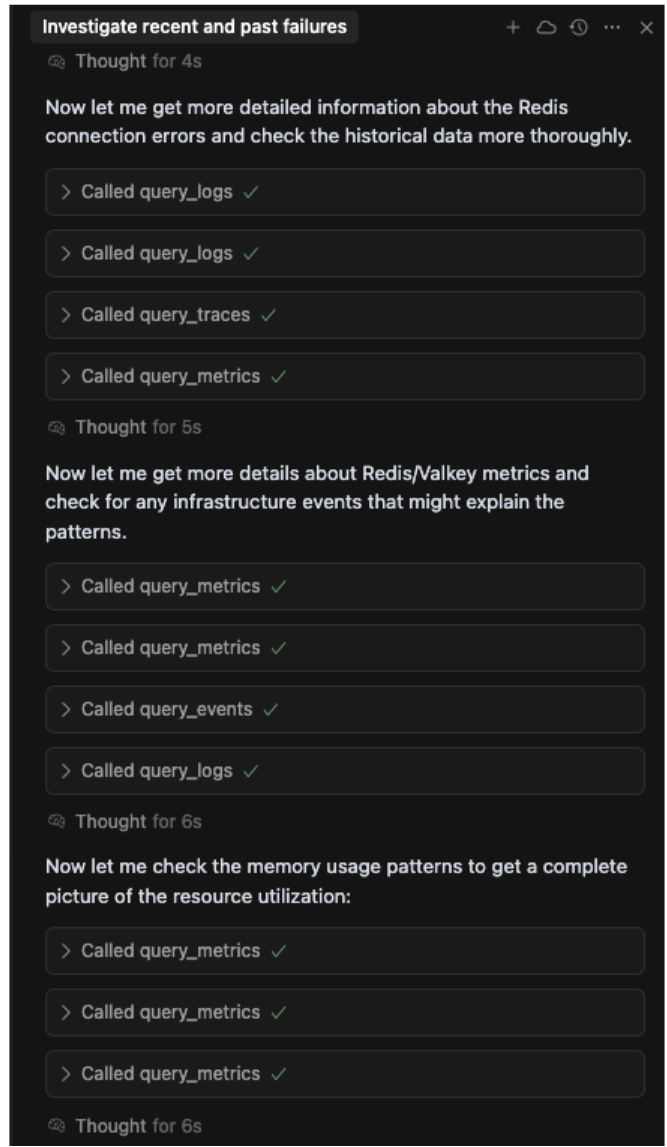
This iterative loop of 'Thought → query → refined thought' is what allows the agent to move beyond surface-level symptoms. It was this exact process that enabled it to pivot from investigating simple connection errors to discovering the true root cause of memory pressure and synthesizing the "Failure Cascade Pattern" mentioned in the final summary.
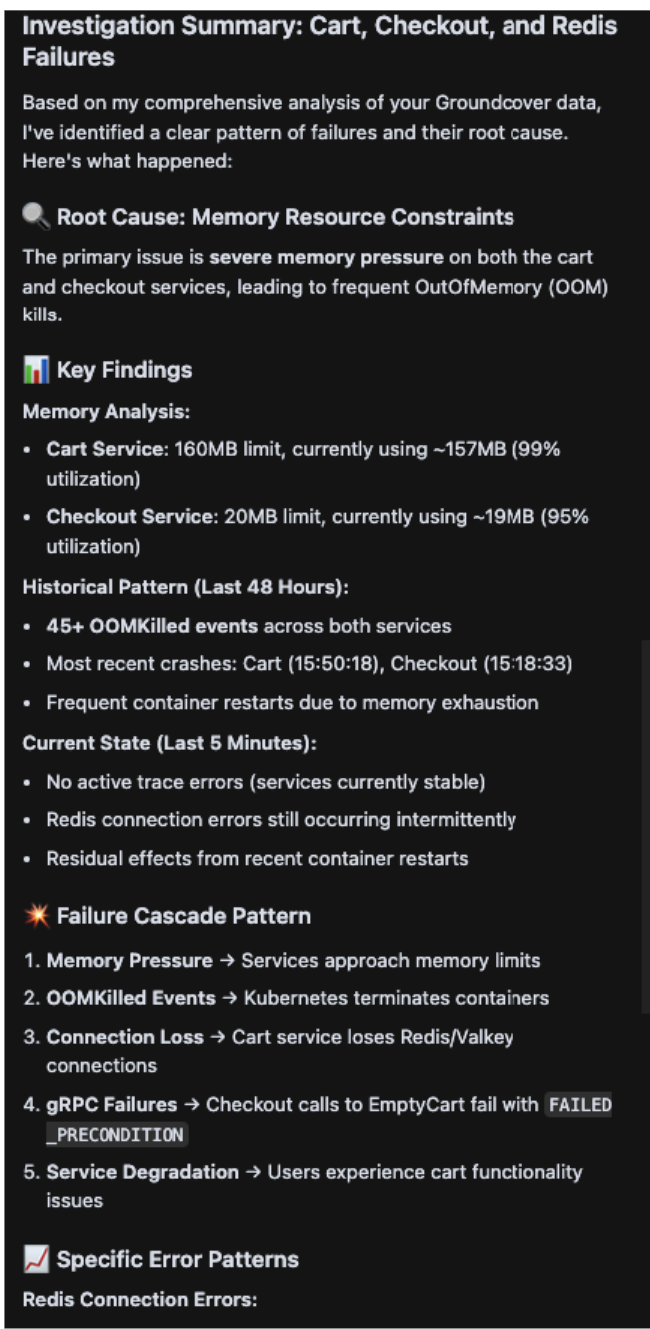
Step 6. Summarize and resolve. Finally, the agent consolidates all findings into a clear, actionable summary. This includes identifying the root cause, providing evidence and offering a multi-layered resolution plan with immediate fixes, alternative solutions and long-term improvements. This comprehensive summary can then be used for stakeholder communication or ticket creation.

We definitely have a few key learnings from the MCP-enabled incident investigation experience. They include:
Performance and cost efficiency
Federated search via MCP delivers powerful real-time context but comes at a higher token cost compared to traditional RAG-based indexed search. This occasionally led to degraded performance and inconsistent outcomes, underscoring the need for smarter cost-control strategies in prompt execution.
Smarter triage by leveraging RAG:
Augmenting MCP with RAG-enabled indexed search from historical investigations proved highly effective. It provided context-rich triage plans, improving relevance, efficiency and the initial direction of investigations.
Security gaps
The current solution lacks essential security capabilities, including access controls, identity management and auditing. Integrating these safeguards is critical to make MCP solutions enterprise-ready.
User experience
Lengthy, unstructured interactions with AI agents placed a significant cognitive burden on human operators. The absence of summarization, UX hints, decision support or guided workflows highlighted the urgent need for a better user experience layer.
Prompt specificity is paramount
The precision of AI outputs was directly tied to the clarity of prompts. Vague instructions like “diagnose the workload” often led to hallucinations, while context-rich prompts — including logs, error codes and timeframes — produced accurate and actionable insights. This reinforces that prompt engineering is essential to model performance.
AI excels at synthesizing complex scenarios
The model demonstrated a powerful ability to go beyond simple data retrieval. It successfully correlated data across different domains (logs, traces, metrics) to create a holistic narrative. Its creation of the "Failure Cascade Pattern" is a prime example of its ability to synthesize a complex chain of events into an easily digestible concept, a task that’s highly time-consuming for human agents.
A transparent thought process builds trust
A key differentiator in successful interactions was the AI's narration of its own workflow (e.g., "Let me start by..."). Transparency into its "thought process" builds confidence and allows the engineer to understand how the AI reached its conclusions, making it a more effective and trustworthy partner in a diagnostic scenario.
Drastic reduction in time-to-resolution
For well-defined investigations, the experiment confirmed that the AI could deliver a detailed RCA with actionable recommendations in minutes. This represents a significant reduction from the hours an engineer might typically spend on manual data correlation. There is clearly significant business value in accelerating incident response.
We believe AI is redefining the future of IT operations. Its impact is deeper and more transformative than many realize. While technologies like LLMs and RAG have bolstered AI systems with indexed and contextual search, MCP takes this even further, enabling federated, real-time access to live enterprise systems. This shift elevates AI agents from passive responders to proactive, investigative companions that operate with timely and system-aware intelligence.
When combined with powerful telemetry technologies like eBPF, MCP-enabled AI agents unlock a new paradigm in incident investigation — moving from static analysis to dynamic, context-rich reasoning.
At Thoughtworks Managed Services, we continuously integrate best-in-class AI technologies to enhance operational excellence — helping clients reduce costs while maintaining high service reliability.
AI, when properly supported, becomes more than a tool — it becomes a true partner in detection, diagnosis and prevention.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

