














Generative AI
AI evals for MCP in AIOps

Vibe coding may be hype, but it hints at how site reliability engineers (SREs)could soon work: side-by-side with AI that embeds intelligence directly into reliability workflows. Among the many facets of SRE, the most immediate frontier for codebots lies in the investigation loop — triage, diagnosis and remediation. Here, the promise is tangible: reducing alert fatigue, accelerating MTTR and raising system quality through faster and more precise fixes or long-term optimization.
Working with vendors such as Qodo, Groundcover and Weights & Biases, we tested how AI assistants can chain together this loop. Our early findings reveal significant potential and exciting opportunities. This post shares those learnings and explores what they signal for the future of trusted AI in SRE investigation.
Investigation sits at the heart of SRE, bridging the gap between noisy alerts and meaningful remediation. It’s where SRE engineers triage incidents, diagnose root causes and propose fixes under pressure — directly impacting MTTR and, ultimately, system reliability.
Unlike resilience engineering or postmortems, investigation is immediate, high-stakes and repetitive, making it an ideal proving ground for AI coding assistants.
Effective AI coding assistants follow a disciplined pattern:
Awareness → Plan → Generate → Merge.
They first build awareness of complex contexts before writing any code. They then plan a resolution carefully — scoping the problem, handling exceptions and aligning with quality or compliance guidance — rather than rushing into implementation.
Next, they generate code that reflects best practices and balances short and long-term benefits. Finally, they assess the potential impact and merge changes into the trunk with confidence.
In the context of SRE investigation, the same pattern (table below.) applies.
| SRE investigation actions | How AI helps | |
| Aware | Triage noisy alerts, scans logs/metrics/traces | Corelates anomalies, deduplicates signals and surfaces the most likely cause |
| Plan | Drafts remediation options (rollback, patch, config change) | Generates structured playbooks, balances decisions, estimates SLA impact and aligns with error budgets |
| Generate | Crafts patches, hotfixes or config updates | Generates precise fixes (script, infra code, runbooks) following best practices |
| Merge | Validates incident fix, pushes through pipeline | Runs safety checks (synthetic tests, rollback readiness, monitoring hooks) and merges with confidence |
Table 1. SRE investigation actions and where AI helps
Human SRE engineers must understand incident context, propose actionable fixes, generate resilient patches and ensure safe integration. This structured loop mirrors how SREs themselves move from triage to remediation — now, AI helps compress the cycle and reduce cognitive load.
In our experiment (Figure 2.), when a developer runs into an incident, they interact first with Qodo Gen through their IDE. This is the main agent they talk to — it helps them think through the problem, plan the next steps and even generate scripts or code to move the investigation forward.
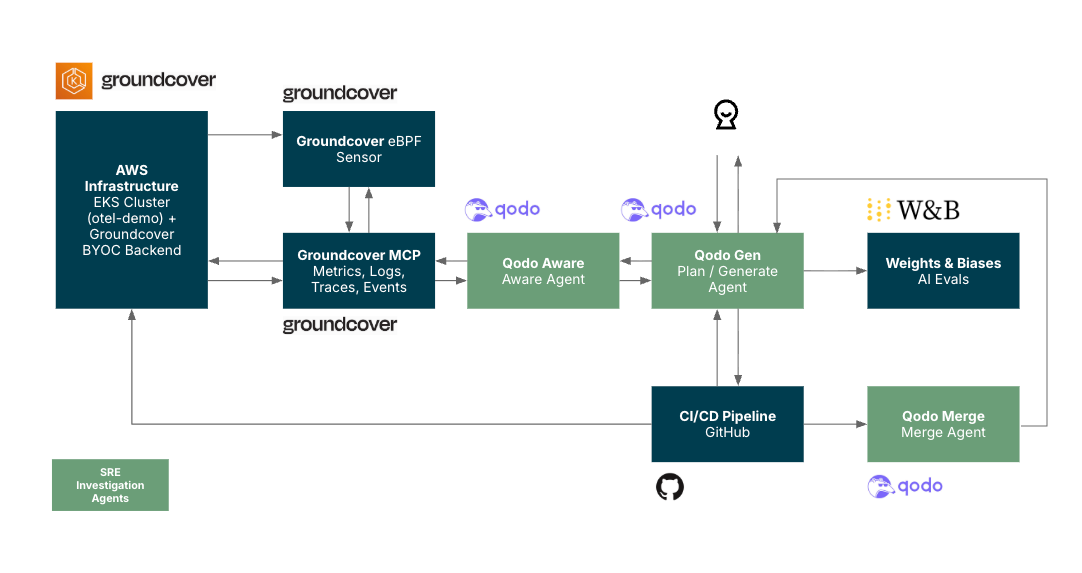
Figure 2. An SRE investigation experiment with Groundcover, Qodo, and Weights & Biases
While Qodo Gen is working, it doesn’t just guess. It calls on Qodo Aware, which goes off to pull the relevant observability context — logs, traces, metrics, past incidents — and feeds that back into the conversation. With this extra awareness collected through Groundcover MCP (Model Context Protocol), the plans and generated outputs from Qodo Gen are more grounded and less likely to miss something important.
Once a potential fix is ready, the developer pushes changes toward a merge. Here, Qodo Merge steps in. It validates what’s about to be merged: running checks, spotting risks, and confirming that the changes align with policies and won’t create new problems. Qodo Merge then reports its findings back to both Qodo Gen and the developer.
All of this is continuously monitored by Weights & Biases (W&B). W&B connects directly to Qodo Gen to evaluate the quality of each output:
Was the plan complete?
Were the generated content factual?
Did the merge validation catch the right issues?
This feedback loop ensures the agents are guardrailed to produce higher-quality outputs over time.
We built evaluation practices into the experiment from the start, using metrics for correctness, performance and reliability impact rather than just productivity.
To ensure our AI assistant wasn’t just a black box, we built evaluation into the experiment from the very beginning. Instead of relying on subjective feedback, we adopted a rigorous, automated framework using Weights & Biases (W&B) Weave to continuously measure the quality and reliability of our AIOps investigation agents.
Our central requirement was clear: for the experiment to be deemed successful, the agents had to achieve a minimum accuracy of 70% across a series of critical performance metrics.
We defined six specific, boolean metrics to score the agent's performance on each investigation:
| Metric | Key question |
| followed_10_steps | Did the agent adhere to the complete, prescribed 10-step investigation methodology? |
| root_cause_analysis | Did the agent correctly identify the underlying root cause of the incident? |
| pr_generation | Did the agent successfully generate a code fix and a corresponding pull request description? |
| provided_solutions | Were the proposed solutions actionable and relevant to the problem? |
| used_groundcover_mcp | Did the agent correctly use Groundcover as its sole source of observability data? |
| hallucination | Did the agent base all its findings on evidence from the data or did it speculate? (False is the desired outcome). |
Table 2. Evaluation metrics to assess AI agent performance.
These metrics aligned the agent’s performance with the same rigor SREs demand from system reliability measures: clear, testable, binary.
We require the agents to evaluate itself. Every investigation ended not just with an answer, but with a structured self-evaluation.
For example, take an incident we staged: “cart service Redis connection failure.” After the investigation, agents completed their run — triaging logs, analyzing observability signals and proposing fixes — one agent had a final mandatory task. It was instructed to programmatically update a Python file (investigation_data.py) with its results. In this file, the agent recorded (Figure 2.) its full response and then scored itself against the six boolean metrics, marking each as True or False.

Figure 2. Agent self-evaluation results
After completing its self-evaluation, the agent’s work did not end with its own judgment. The final step calls our W&B evaluation script (evaluation.py). The script compared the agent’s self-reported metrics against ground truth, calculated accuracy, and logged results into Weave (Figure 3.).
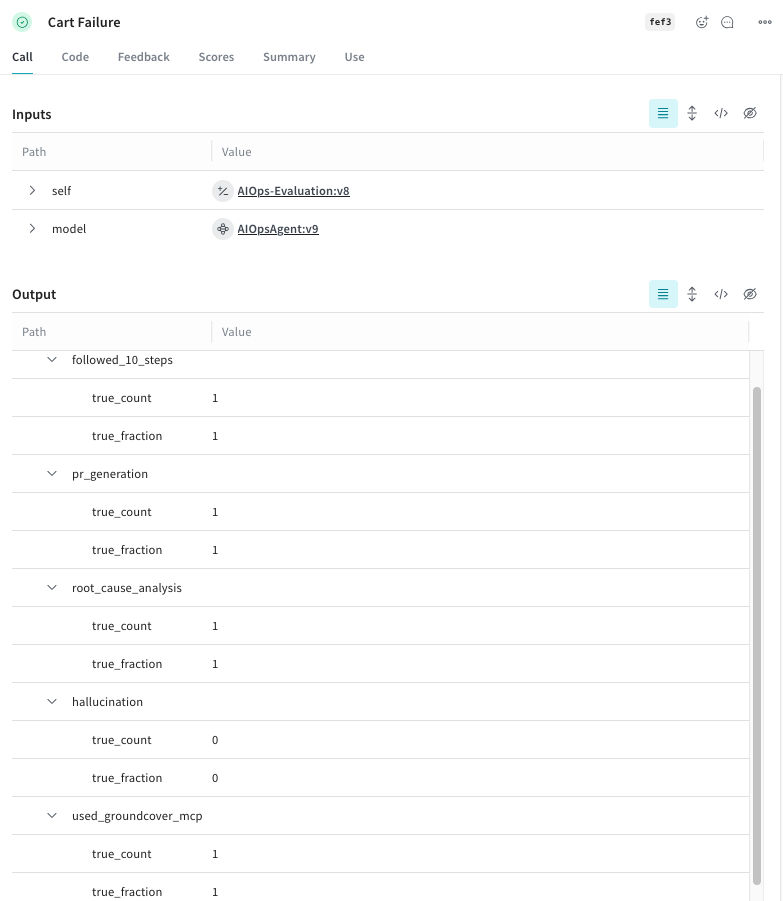
Figure 3. Complete Evals results in Weave
This chained seamlessly to self-evaluation: the agent first scored itself, then submitted that score for independent LLM-as-a-judge evaluation. The result was an automated feedback loop where every investigation ended with both reflection and external scoring — embedding reviews and a practical form of meta-awareness into the workflow.
We found real gains in reducing toil and improving signal-to-noise but also ran into gaps in explainability, governance and trust.
This experiment was more than just a technical proof-of-concept; it provided critical insights into building trusted and effective AI systems for SRE. Our agent successfully met the >70% accuracy threshold, proving that a well-designed AI can automate complex incident investigations and significantly reduce engineering toil.
However, our most significant findings were not just about the agent's performance, but about the process of building and validating it.
An "evals-first" approach is non-negotiable. Building a rigorous, layered, automated evaluation framework from day one was the single most important factor in the project's success. Using Weights & Biases Weave allowed us to move beyond subjective assessments and define a clear, measurable bar for what "good" looked like. This discipline is essential for building trust in any AI system.
Self-reflection creates feedback. The breakthrough moment was designing the agent to be an active participant in its own evaluation. By prompting the agent to self-assess its performance and trigger its own validation script, we embedded a layer of accountability directly into its core logic. This creates a powerful, automated feedback loop where the agent isn't just a tool, but a system that reflects on and reports the quality of its own work.
Trust is built on evidence, not promises. While the agent performed well, we confirmed that true trust requires more than just a high accuracy score. To be fully adopted, the agent must provide complete explainability for its decisions, operate within clear governance boundaries and demonstrate its reliability over a wide range of scenarios.
The AI coding market has room for improvement. There’s space for AI coding providers to differentiate by offering transparency, ease of integration with LLMOps platforms and native connectivity to observability stacks. True adoption will depend on how well these assistants embed into enterprise reliability workflows, not just how fast they generate or merge code.
The path ahead lies in scaling these experiments, embedding evaluation discipline and co-designing with engineers to create trusted AI for SRE. Our experiment with the SRE investigation agents isn’t an endpoint, but the foundation for a broader vision.
Stage 1: Broaden real-world coverage
Train agents on production incidents to improve diagnostic accuracy and handle diverse failure modes in the real world.
Stage 2: Automate eval-to-retrain loop
Build a CI/CD pipeline where incidents trigger automated testing, logging and retraining for continuous refinement.
Stage 3: Expand to new observability platforms
Develop new data connectors and integrate with multiple observability platforms to fit diverse SRE ecosystems.
Stage 4: Extend across the SRE value chain
Build additional agents for incident communication, postmortems, risk analysis and chaos engineering — expanding impact beyond investigation.
Ultimately, our vision is an AI agent–infused SRE value chain: investigation, remediation and reliability engineering supported by agents that are context-aware, platform-agnostic, self-reflective and governed through robust LLMOps practices. In this model, embedding intelligence into reliability workflows isn’t hype but a reality. To do it effectively we need to lead with an evals-first discipline and build within an open ecosystem of technology and service providers.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

